
Abstract
Imputation fixes broken data. Methods are from making it constant mean to clustering, regression and generative networks. What if you really care about each sample and treat it as a real object to reconstruct and not as a fuel for GPU. Reverse training learns the data distribution inside a neural network weights and then accurately selects most suitable input features that are missing. This selection is done by reverse training, when the neural network weights are locked and the input layer is loosen for optimization.
Imputation Methods
In order to fill the data gapes we need first to identify them. Oftenly people misuse NULL, “”, “ ”, “0”, 0, None, Nothing, NULL etc. Thus some deduction is required to judge where the data is really missing. If the problem does not look complex and we need this dataset cleaned only for training or evaluation purposes – it is ok to remove a small amount, especially if it will not corrupt the distribution.
If we decide to fill the data gaps with real numbers, we can go with all kinds of averages, use linear regression or dataset factorization (especially agglomerative clustering) in order to find nearest data with values filled.
With the VAE and GAN (or even LLM) introduction we can also use generative approaches, however they are not deterministic and in the case of careful data recovery we might not want to have anything that has been derived from a random seed.
We also can use regular AutoEncoders to learn the data distribution and then pass corrupted data with zeros as an input. It works just fine when the data corruption is on the level of outliers:

Experiment using AutoEncoder
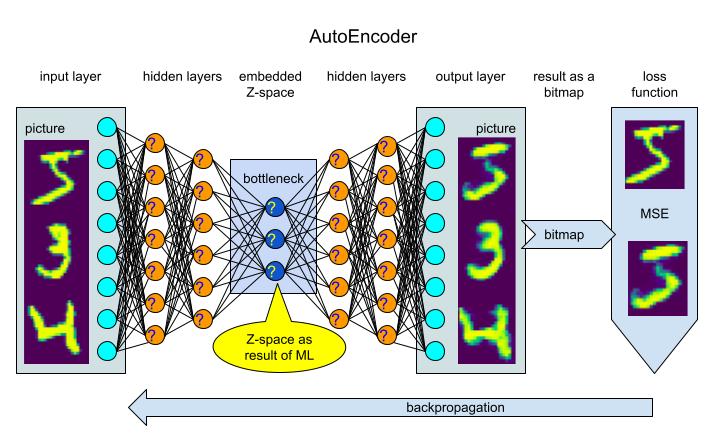
Let’s review the architecture of a regular AutoEncoder. It passes data through the z-space bottleneck encoding it and then decodes it trying to fit the original input.
As we might see the ML is happening inside the internal neuron layers (question marks on the picture). The process of training is pretty straightforward and does not require any data annotation.
What if we have a bigger amount of data missing, for example one third of the MNIST digit will be just filled by zeros. And we will pass this corrupted data through the trained AutoEncoder:
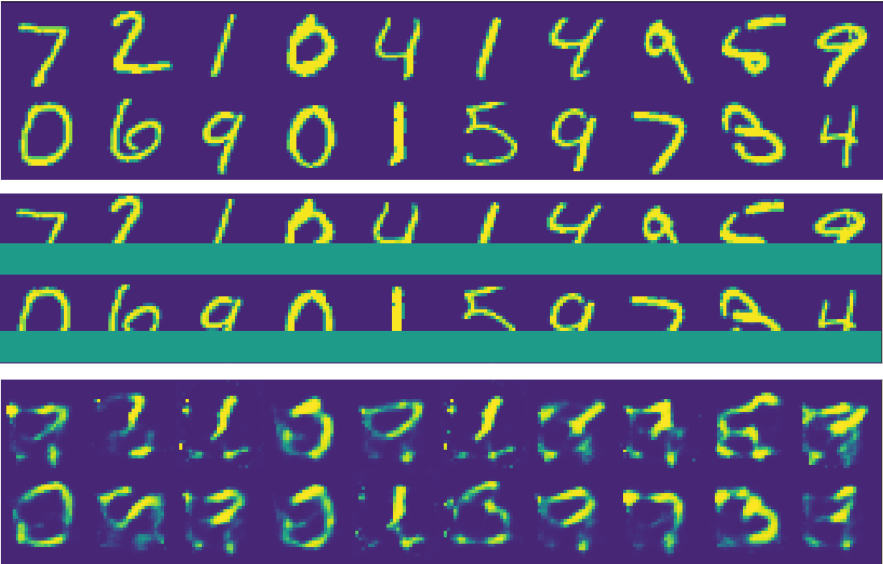
We can see original and then corrupted by 36% lines of digits. The final line represents what pretrained on MNIST AutoEncoder can recreate in the case of regular use.
We need to use some kind of business metric, thus let it be accuracy calculated over all points intensity rounded to 0 and 1 (on the test dataset of course). Calculations show Accuracy as 90.56%, meaning nine out of ten pixels when converted from grayscale to binary mode will be correct in the whole digit picture. And this sounds ok, but does not look correct. If you examine the digits in the third line you can barely guess what the number is displayed.
Experiment with Reverse ML
What if we have enough time to take care of each data sample and recreate it using reversed ML. This means we take the very same pretrained on MNIST AutoEncoder and freeze all the weights in hidden layers. Same time we will allow the missed input data to be trained sample by sample:
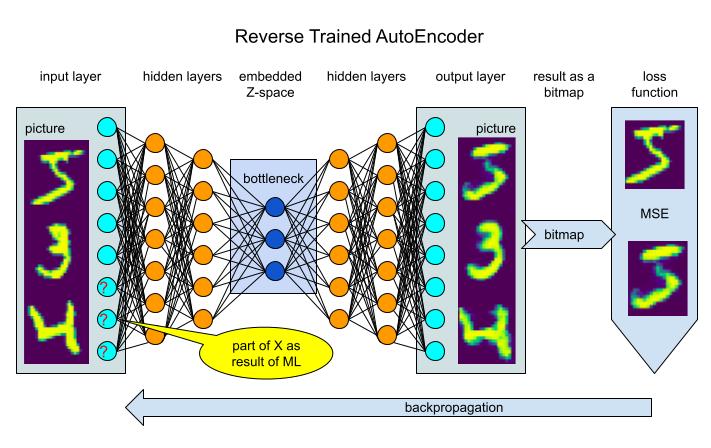
As we can see on the picture the weights now are in the lower part of the input layer (question marks). And we use the same MSE loss function, just adding a spherical regularization on the bottleneck and a dropout after the input layer:
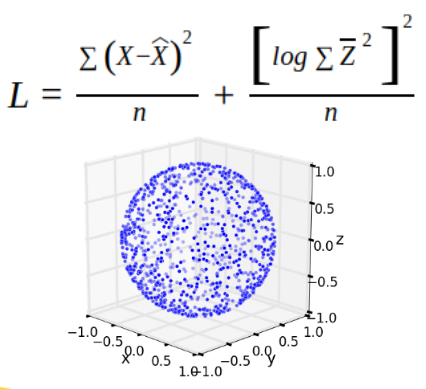
After short ML training cycle we can show the weights on the input layer that was restored, or actually imputed by the Reverse ML:

The result looks promising, a bit noisy, thus we just pass this reconstructed input again through the AutoEncoder and it will nicely clean it for us:

The accuracy was 96.22% this time and the picture looks more natural.
Summary
As result we obtained additional 6% of accuracy of the data imputation, the visual result is way better than a regular AutoEncoder:
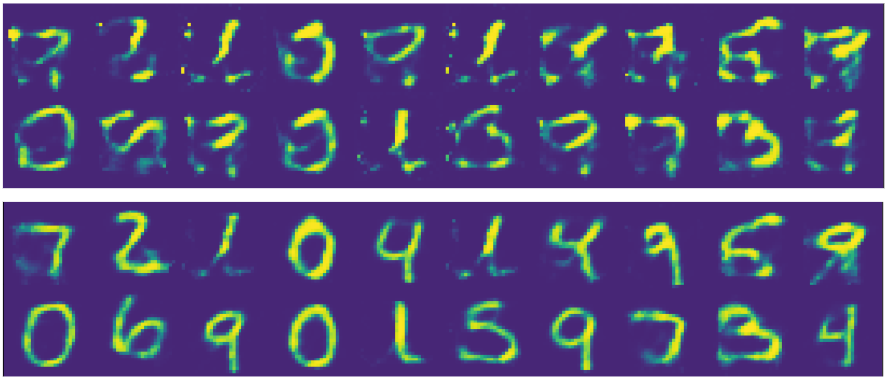
The Reverse ML method requires more computational resources and is slower. It gives better accuracy than classical methods and it is more stable and simpler than generative models that depend on a random input.
Credits
You can found the notebook with all the code: ReverseTrainedAutoEncoder-MNIST.ipynb
you might also like…

Researching Visual Question Answering: Bridging the Gap between Humans and AI
Introduction The goal of this project is to offer regular users and developers the chance to engage in practical visual... Read more
Enhancing Recommender Systems with Hybrid Knowledge-Graph Attention Networks (KGAT)
In the competitive digital market, keeping customer interest is crucial for any business. Recommender systems are key tools in this,... Read more