
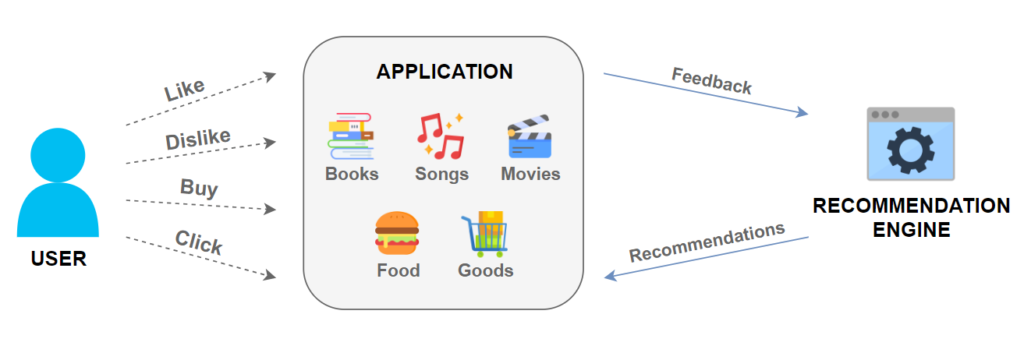
In the competitive digital market, keeping customer interest is crucial for any business. Recommender systems are key tools in this, helping to keep users engaged and loyal. Graph-based recommender models are particularly effective, and able to handle complex data and relationships within their networks.
Especially for businesses with frequently changing products, finding a recommender system that can adapt is essential. Our KGAT-based system is built for this kind of environment, making use of a variety of data to provide recommendations that keep up with your product’s development.
KGAT (Knowledge Graph Attention Network) is one such system that initially focused on item-side information to guide user preferences. By integrating user-side features into the KGAT framework, we’ve transformed it into a hybrid model, a pioneering architecture that not only understands items but also the multifaceted users interacting with them.
Why graph recommender?
Graph-based architectures for recommendation systems represent a transformative leap from traditional matrix-based models and offer a compelling suite of benefits that can significantly enhance the performance and relevance of recommendations:
- Complex Relationship Mapping: Graphs are adept at illustrating intricate relationships between users and items, capturing the subtle nuances of user preferences.
- Scalability: They can easily scale by adding new users, items, and interactions, making them ideal for growing businesses.
- Improved Recommendation Quality: The interconnected nature of graphs facilitates more accurate predictions by considering the broader context of user-item interactions.
- Sparse Data Management: Graphs can handle sparse datasets efficiently, making meaningful connections even with limited user interaction data.
In practice, sparse datasets are a challenge, especially with constantly changing products. This variety can result in gaps where interactions are minimal or entirely missing, posing a challenge for traditional matrix factorization methods which require dense data to function optimally. Graph architecture offers a practical solution by naturally incorporating various data types into a single model. This approach allows for effective recommendations even when direct user-item interactions are limited, making KGAT a more suitable option in these situations.
Knowledge graph structure
At its core, a knowledge graph is an intricate network that links entities—such as users, items, and their features—through various types of relationships. It organizes information into nodes and edges. Nodes represent entities (e.g., users, products, categories) and edges depict their relationships (e.g., purchased, viewed, rated). This allows the creation of a detailed map of interactions and interests. It’s a versatile structure where additional layers of information can be integrated, such as location info, social networks, and semantic information, enabling a comprehensive understanding of the user’s context and environment.
KGAT modification
The original KGAT model operates by using item-side information to construct a knowledge graph that captures the relationships between items and user interactions. It applies an attention mechanism to this graph, which allows it to learn the importance of different items and their features, thus generating recommendations based on the items’ interconnected attributes.
The modification of the KGAT model to include user-side features is a strategic enhancement designed to refine the accuracy and relevance of recommendations further. This modification enriches the model’s understanding of user behavior and preferences, leading to predictions that are not only based on item attributes but also shaped by individual user characteristics, which significantly improves the relevance of the recommendations provided.
As the first step, we created a comprehensive knowledge graph that represents users, items, their attributes, and the interactions between them. This graph is constructed with nodes representing both users and items, while the edges represent the interactions (ratings) or relationships between users or items and their features.
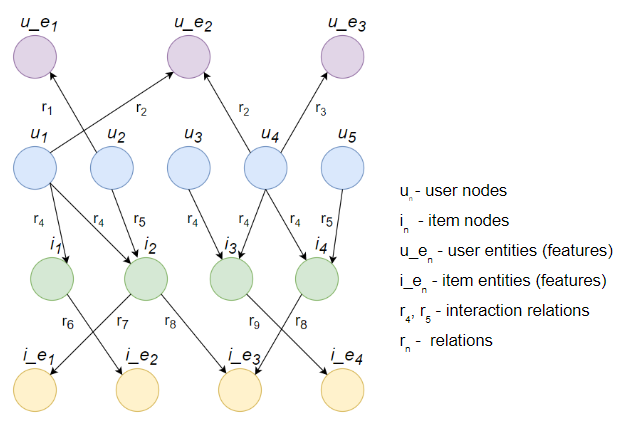
It is crucial to differentiate between various types of interactions; for instance, positive and negative ratings are treated as distinct relations, each with its unique influence on the user’s preference profile.
Following the construction of the knowledge graph, the model training process is divided into two phases. In the initial phase, the model uses direct user-item interactions to develop robust user and item embeddings. This is achieved by creating a user-item graph and applying the Bayesian Personalized Ranking (BPR) loss function. BPR works on the principle that a user prefers an item they have positively interacted with over items they have a negative experience with.
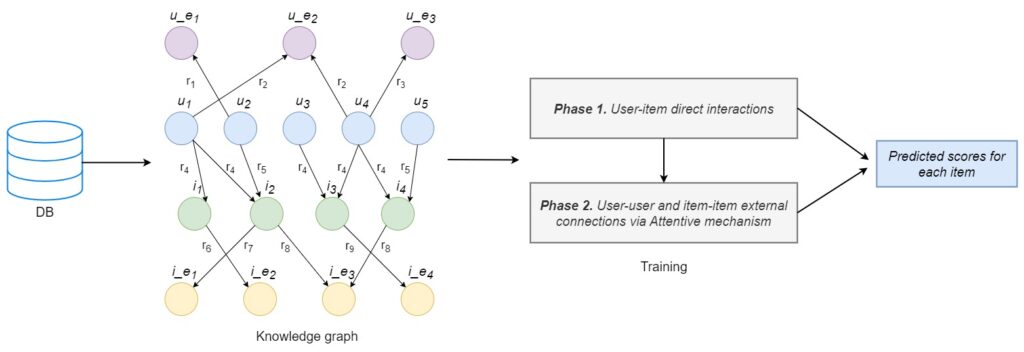
The second phase of training broadens the scope to include all additional connections and external side information. This phase builds upon the user and item embeddings obtained from the first phase, integrating side information such as user demographics or item categories into the model. Attentive embedding propagation layers are employed to blend this diverse data into a unified vector. These layers recursively propagate embeddings from the neighbors of a node to refine its representation.
During this propagation, a knowledge-aware attention mechanism is used to determine the weight of each neighbor’s influence. This mechanism ensures that each feature, whether related to the user or the item, is appropriately factored into the overall recommendation. It’s a process that not only considers direct interactions but also the broader context of those interactions, thereby enhancing the model’s ability to make nuanced and contextually aware recommendations.
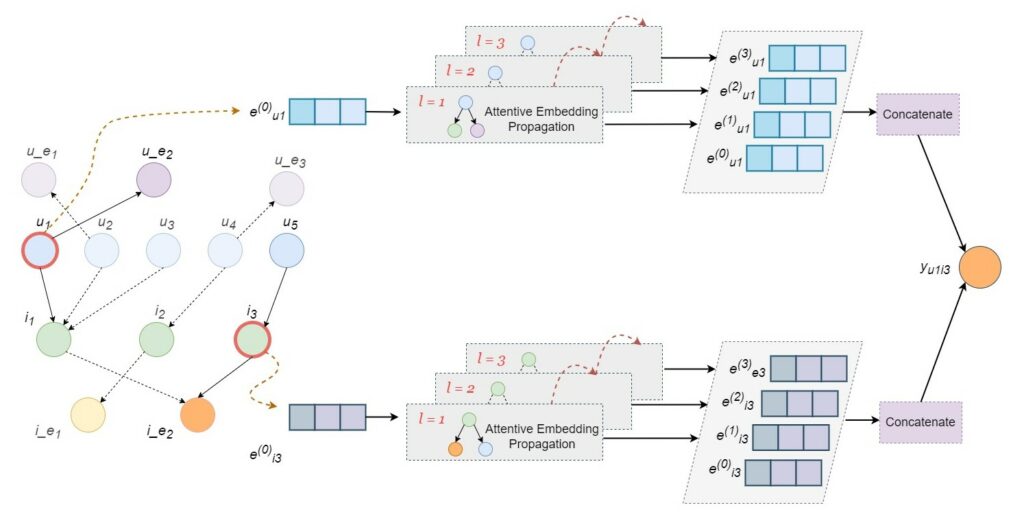
Through this systematic approach, the KGAT model transforms into a hybrid system that captures both direct user-item preferences and the wider context of those preferences, resulting in a sophisticated recommender system capable of delivering personalized user experiences.
Evaluation
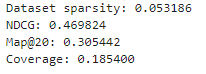
One reason for utilizing Knowledge Graphs (KG) is to mitigate the sparsity problem that often constrains the effectiveness of recommendation systems. It is challenging to create ideal representations for users with minimal interactions. We evaluated the adapted KGAT on a specialized dataset characterized by low sparsity and obtained the following metric outcomes:
Also, we evaluated the CatBoost model trained on the same dataset and compared metric results:
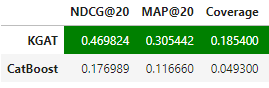
The KGAT model has shown better performance in this evaluation compared to CatBoost.
Limitations
One of the primary challenges is the complexity of the knowledge graph itself. As the number of users, items, and features grows, so does the graph, which can lead to increased computational demands. This complexity can affect the model’s scalability and performance, particularly when processing real-time updates or handling large-scale data
Summary
KGAT, enhanced to include user-side features, offers more personalized and contextually relevant recommendations using a comprehensive knowledge graph. The performance of KGAT, as demonstrated by key metrics, surpasses traditional algorithms like CatBoost, providing both higher accuracy and a broader diversity of recommendations. However, the system’s complexity presents ongoing challenges. Despite this limitation, KGAT’s ability to dynamically adapt to new information and model complex relationships holds promise for businesses looking to leverage advanced recommender systems.
you might also like…
Data Imputation using Reverse ML
Abstract Imputation fixes broken data. Methods are from making it constant mean to clustering, regression and generative networks. What if... Read more

Document Classification and Tagging with LLM
Introduction Documents and databases can handle information, however, the difference is in the form. Documents and articles have unstructured but... Read more