

Introduction
Documents and databases can handle information, however, the difference is in the form. Documents and articles have unstructured but human-readable forms of information. Having tons of documents leads companies to organize them in DMS (document management systems) or in clouds with such functionality.
There is a need to keep documents sorted by the document type or to tag articles by some topic. We solve such tasks by performing the following steps:
First of all, we do need to convert a document to a text. This is sometimes called OCR, better to say file content extractor using an available set of special libraries, such as Textract, NLTK, or Langchain. Actual optical character recognition is required only for images and images inside text files. We usually use a combination of Google Tesseract and cloud services (AWS or Azure).
To obtain document class or type one can use OpenAI or any other Large Language Model using simple prompt engineering like following:
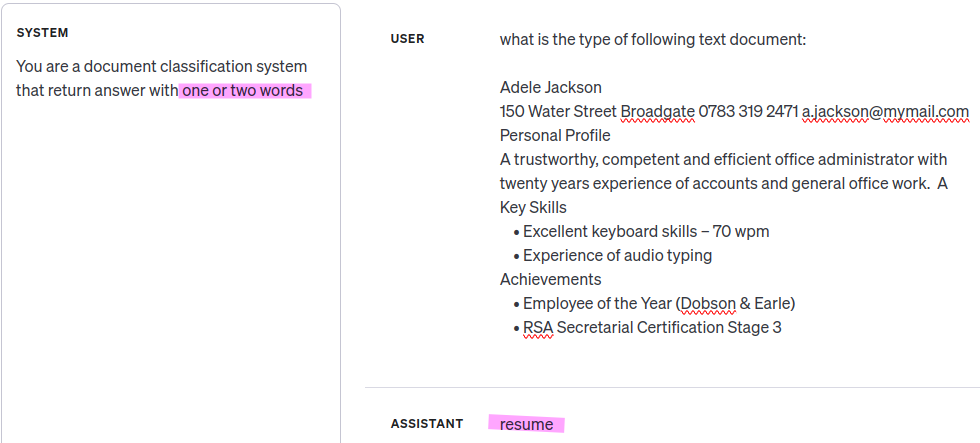
However, for practical use, we need to limit the output to a specific set of classes and inquire about each class separately, asking, ‘Is this document a CV?‘ In this scenario, we will receive a ‘Yes/No‘ answer, which aids in resolving the ‘Resume/CV‘ class ambiguity. This approach will require more calls to LLM. For tagging text articles, we need to request multiple tags (multilabel classification instead of multiclass), and this will also consume more time and LLM resources.”
Example or article tags: Economy, Europe, Taxes and Rules
To solve this problem we use text Embedding (or conversion of text to vectors of numbers). The text content has to be split into reasonable chunks with some overlapping. Numerical parameters have to be explored depending on the document type and whole corpus characteristics. Extracted chunks have to be lined into paragraphs, lines, and word tokenizer or splitter. Then these blocks of text will be processed by an LLM with an embedding function that will return a set of numbers (vector of embeddings) for each text chunk. This information along with text will be stored in a vector database. LLM for embeddings can be used from OpenAI or from deployed transformer models from HuggingFace. Such deployment will require a medium-sized GPU computer.
After obtaining vector representation of text documents we engage in classical supervised machine learning. Even basic SVM (Support Vector Machines) can perform with good prediction over text classes or tags. More complex ML models (like XGBoost or DNN) tend to overfit, while SVM can be trained and validated on the same dataset. This is very handy for small amounts of annotated data. This is an example of such a multi-label classification report of document classes trained on a relatively small amount of data (support column):
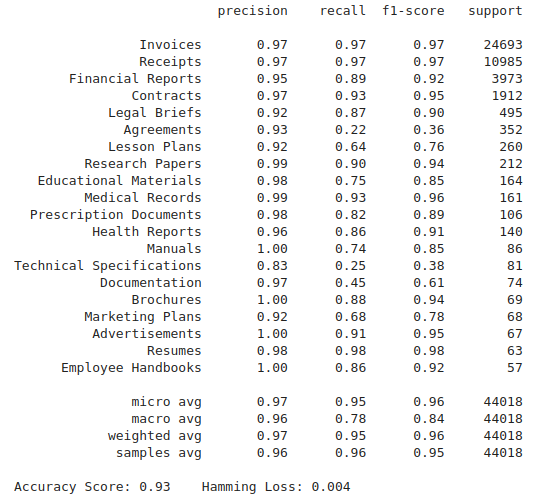
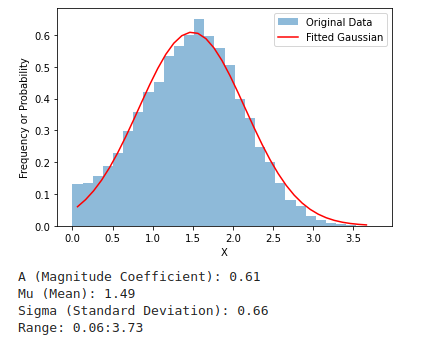
As a result of a machine learning model, we are receiving some predictions and a confidence score. In the case of the SVM model the score has nothing to do with confidence, just some distance number between the point in the 1500-dimensional embedding space and the decision boundary line. And it can be a number from negative to positive infinity. Our customers want to have a confidence score in the 0-1 range, thus we build a special model to cover the SVM distance distribution as a Gaussian curve and then use it for the confidence score in the 0-1 range:
Summary
The integration of OCR, large language models, text embedding, and classical machine learning techniques offers a comprehensive solution for document organization and classification, catering to the diverse needs of businesses dealing with vast amounts of unstructured information. This approach not only streamlines document management but also enhances the accuracy and efficiency of document classification processes.
At MindCraft.ai, we possess the expertise to implement these advanced solutions and are ready to provide consultation whenever your business requires such capabilities.
you might also like…
Enhancing Recommender Systems with Hybrid Knowledge-Graph Attention Networks (KGAT)
In the competitive digital market, keeping customer interest is crucial for any business. Recommender systems are key tools in this,... Read more

A digital twin of terrain – 3D model from satellite images
Hypothesis Any new project begins with an idea, undergoes development through information gathering and testing. The idea that initiated our... Read more