

Introduction
The goal of this project is to offer regular users and developers the chance to engage in practical visual question answering using their regional language. The current system employs the Ukrainian language, but it can be adapted to other languages, such as Spanish, German, Italian, and more.
VQA description
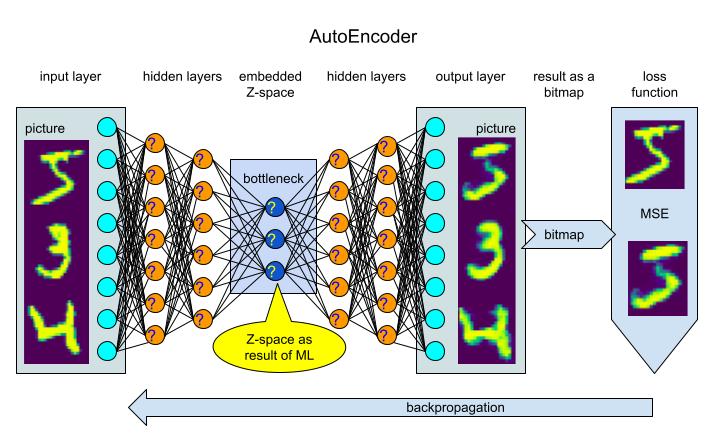
Visual Question Answering (VQA) is a field of research that combines computer vision and natural language processing to enable machines to answer questions about the content of images or videos. The goal of VQA is to create algorithms that can “understand” the content of visual data and provide accurate and meaningful answers to questions posed in natural language (see Figure 1).

System architecture
After considering various types of software architecture, the client-server architecture was chosen as the most suitable for the specific case. Our system needs to be able to accommodate multiple users while properly distributing the workload and processing users in a queue. The client-server architecture is precisely convenient for implementing this scenario.
Deployment diagram
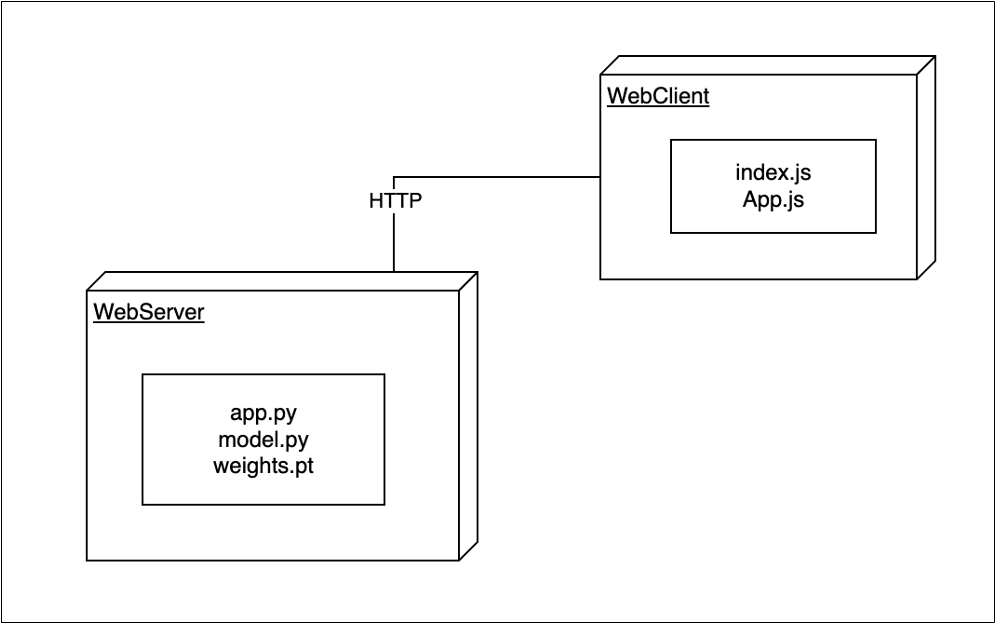
The Deployment Diagram is a type of diagram that illustrates the system’s architecture during execution, including computational nodes, virtual environments, and entities responsible for interaction between individual nodes.
The diagram depicts a web server and its components such as “app.py” (the main file where the server is created and all necessary URL mappings are defined), “model.py” (a file describing the structure of the neural network), and “weights.pt” (trained network weights used for predictions).
It also includes a web client consisting of “index.js” (responsible for the visual component of the main window and interaction with the server) and “App.js” (responsible for deploying the server and opening the main page). The deployment diagram is graphically presented in Figure 2
Back-end
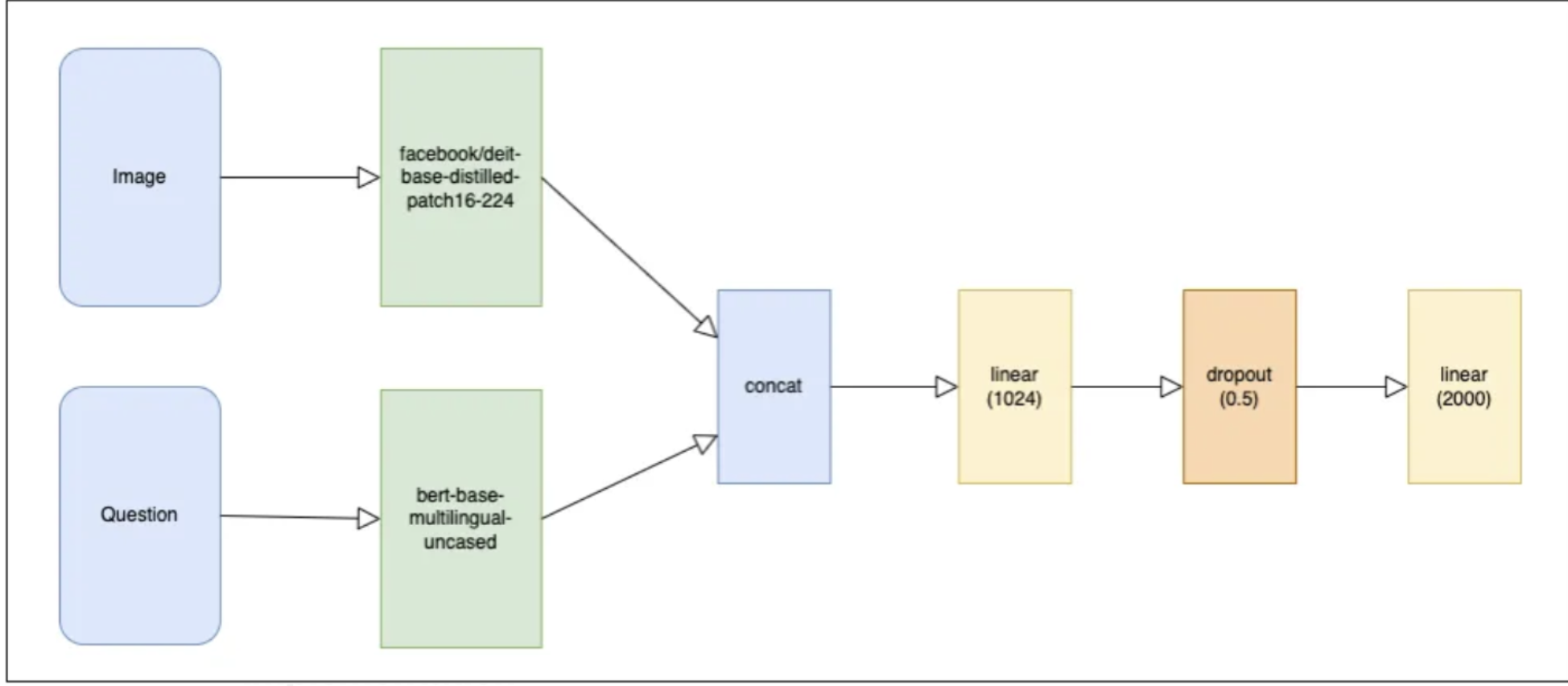
The server-side of the software system will be implemented in the Python programming language using the FastAPI framework for creating the backend server. Several pre-trained models were employed as the architecture of the neural network.
The “facebook/deit-base-distilled-patch16–224” was used as the visual transformer, and the “bert-base-multilingual-uncased” was used as the textual transformer, responsible for extracting visual and textual features.
These features were then combined into a single vector through concatenation and further processed using several fully connected layers of the neural network.
The output consists of 2000 classes, representing the set of possible answers from the VQA model (see Figure 3).
Front-end
The client side of the software system will utilize technologies such as HTML5, JavaScript, CSS, and the JavaScript framework React.js. To run the web server, a Node.js server will be required. The library Axios will be responsible for sending requests to the backend server.
Implementation
Research
Currently, VQA methods allow for generating complete sentences as the output of the neural network’s prediction. However, this requires significant computational resources. In this work, several research studies were conducted, leading to a slight modification of the original VQA task without a significant impact on its performance.
The first research study focused on analyzing the word count as the answer to a question. The results were obtained for the training (train2014) and validation (val2014) subsets of the COCO dataset (see Figures 4 and 5).
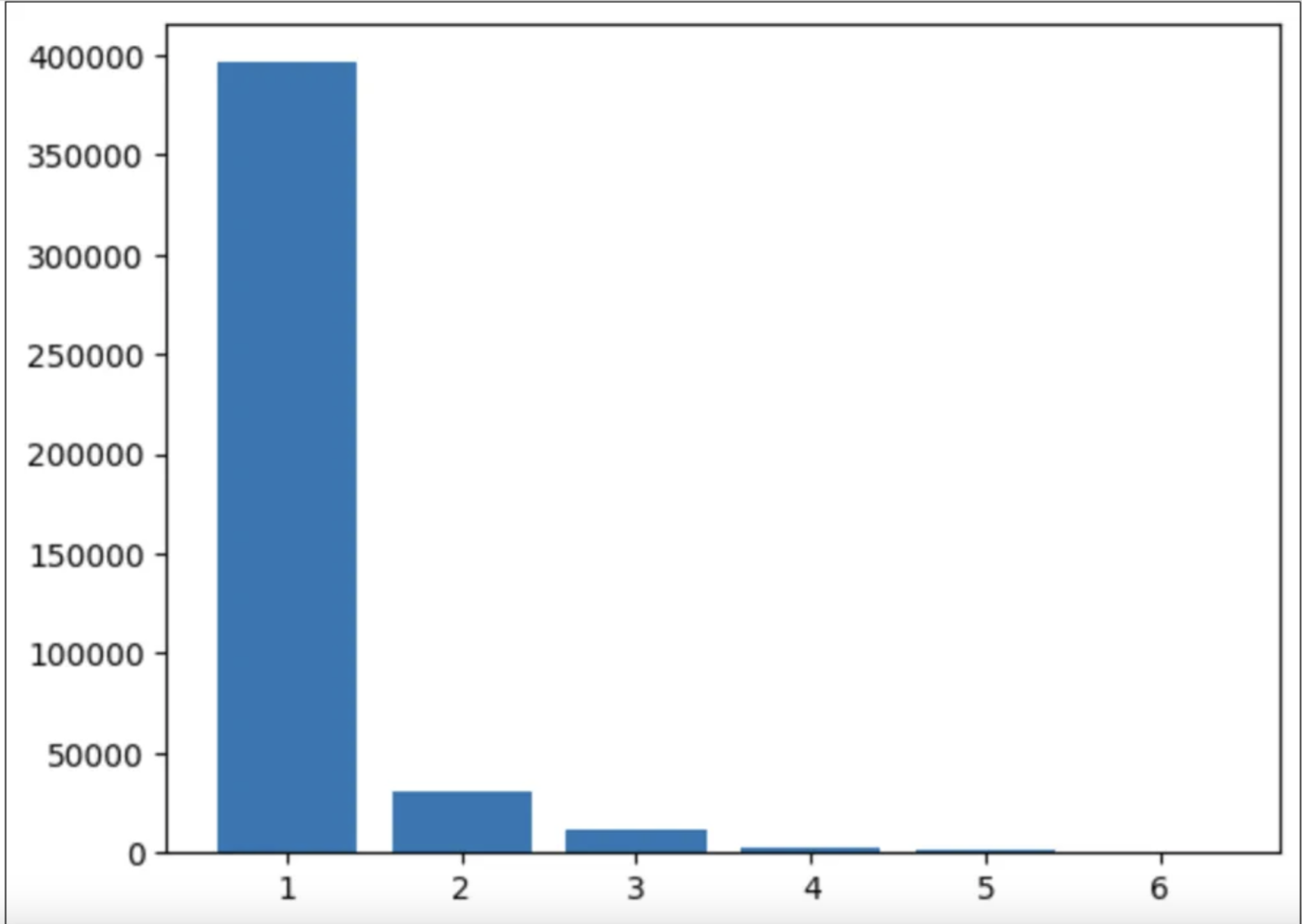
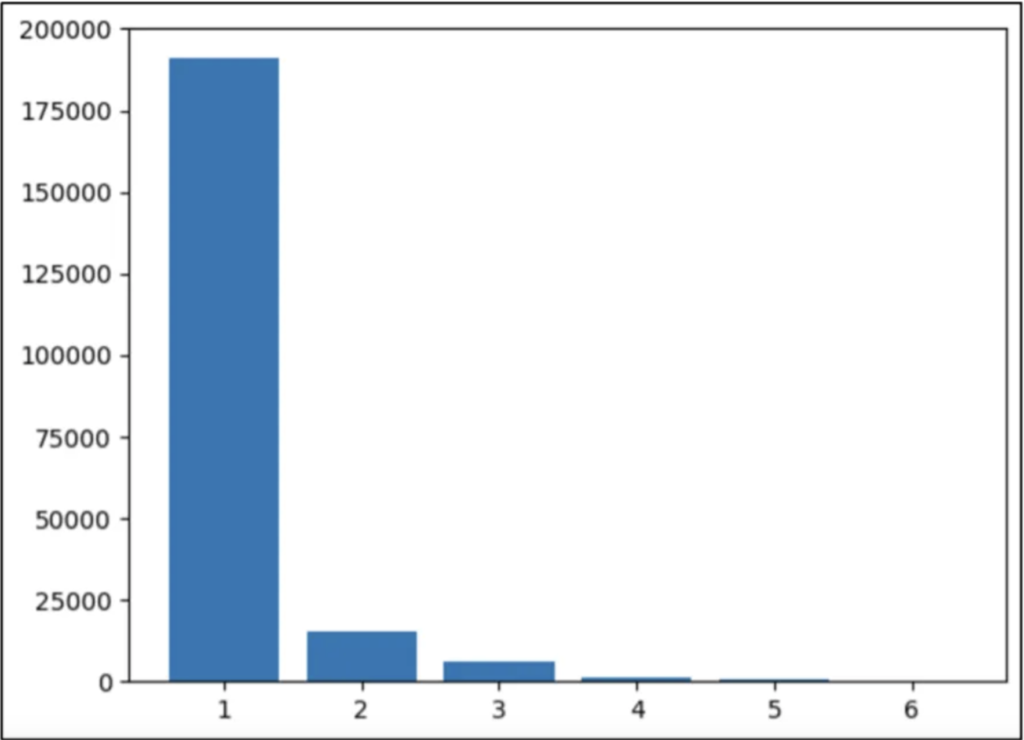
Based on the above graphs, the decision was made to transition from sentence-based results to single-word results, as one-word answers cover up to 89% of the responses.
The second research study focused on the number of different words used as answers. This factor affects the training and prediction time of the network.
As a result, it was calculated that the top 2000 most popular classes cover more than 99% of the answers. Therefore, it was decided to limit the scope to these 2000 most popular words.
Data preparation
The obtained 2000 words were saved in a text file, where each line represents one class for training the model.
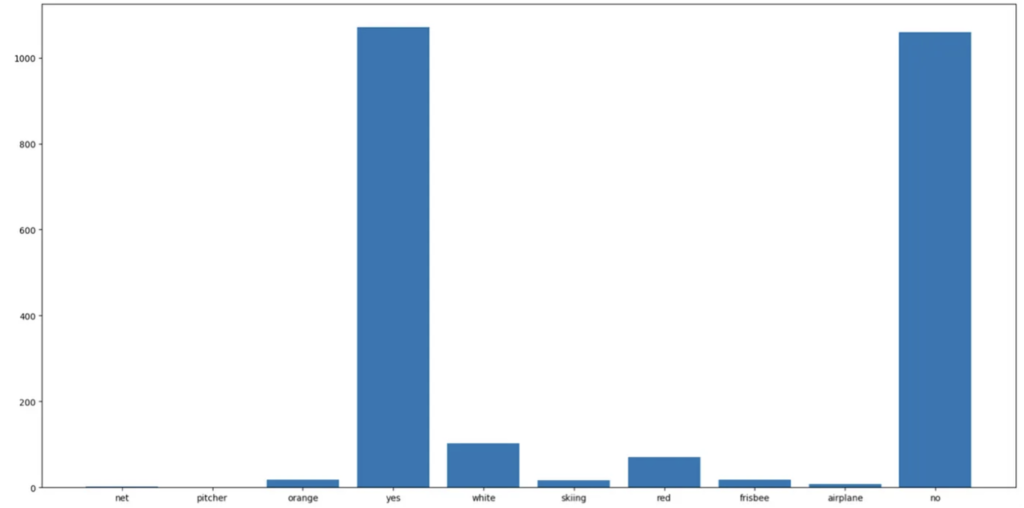
Furthermore, among the selected top 2000 classes, the visualization of the 10 most popular classes was generated (see Figure 6).
To facilitate training, it was necessary to transform the input data from the COCO dataset into a convenient format for training and validation. The original annotation format is shown below.
To change the annotation format, a separate script was created to transform the data from one format (original JSON files) to a processed format (CSV files with single-word answers to the provided questions).
As a result, a CSV file with processed data was obtained, which can be used to begin the model training (depicted below).
Currently, we have processed CSV files for training the model, but they are all in English. To improve the model’s accuracy when using the Ukrainian language, we need to incorporate a Ukrainian dataset.
Since no publicly available resource with annotations for the desired Ukrainian dataset was found, the decision was made to translate this large dataset ourselves. The total size of the dataset is approximately 600,000 questions and answers that need to be translated from English to Ukrainian.
For this task, the machine learning model “Helsinki-NLP/opus-mt-en-uk” was utilized. This model specializes in translations from English to Ukrainian. Beneath presents the code snippet for using the aforementioned model to translate questions from English to Ukrainian.
An attempt was made to translate all the answers to the questions using machine learning methods. However, such models work well for sentences and texts, but not for single words. They lack the necessary context for accurate translation.
Therefore, for translating the answers to the questions, the Translate library was employed, which utilizes the Google Translate API.
Additionally, the decision was made to translate only the aforementioned top 2000 answers selected as the model’s outputs. The code for translating answers from English to Ukrainian is provided in the following section.
Model training & validation
To prepare the training and validation data, a dedicated class was created to transform the information recorded in tables (images, questions, answers) into data understandable to the model — visual and textual features.
The next step after data preprocessing is the creation of the machine learning model. The section below illustrates the creation of the model class along with all its components used for machine learning.
Additionally, the key function during training and prediction of the model is the forward function, the implementation of which is shown below.
The Wu-Palmer similarity (WUPS) metric was utilized to calculate the similarity between words. This metric relies on WordNet, which is part of the nltk library. WordNet represents a network where words are connected based on their meanings, grouping synonymous words together. Figure 7 provides a schematic representation of WordNet.
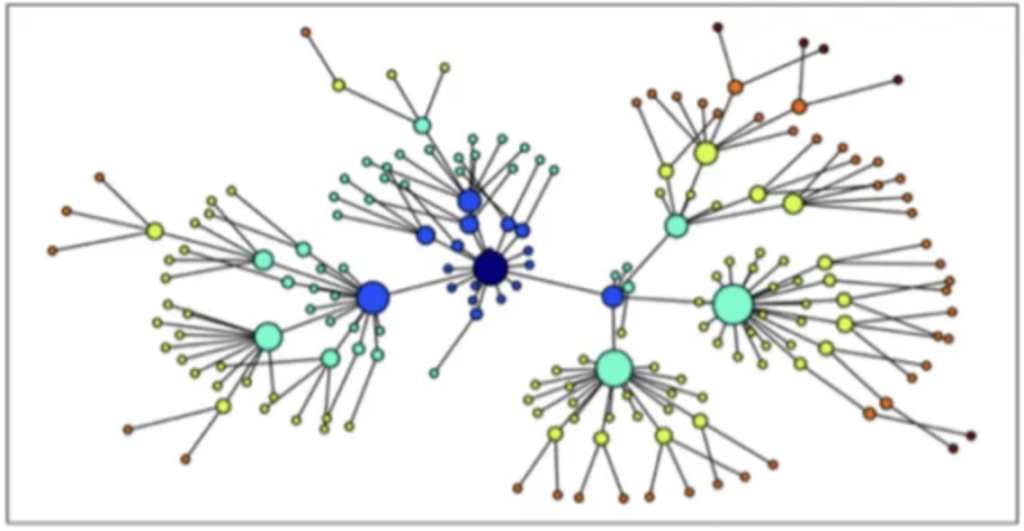
Figure 8 presents the formula used to calculate the WUPS similarity. It involves finding the lowest common ancestor for two words and calculating the similarity based on the depths of each word individually and the depth of the lowest common ancestor.

For the convenience and efficiency of the training pipeline, the TrainingArguments and Trainer from the Transformers library were employed. These components are specifically optimized for training and prediction on transformer-based models (see sections below). Part of the code originated from the Tezan Sahuarticle.
The model was initially trained for 5 epochs on the English dataset to ensure that it understood the semantics of the English language and learned weights on the original dataset. After that, the model was trained for an additional 1 epoch on the Ukrainian dataset. The results obtained are depicted in Figure 9.
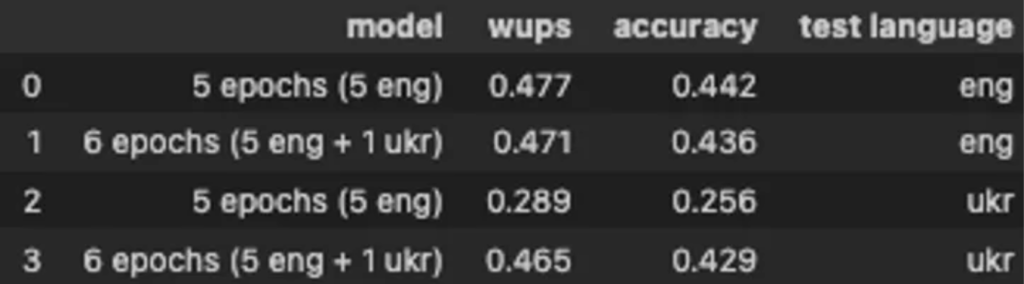
From the metrics, we can conclude that fine-tuning the model on the Ukrainian dataset had a significant impact on the model’s performance for the Ukrainian language. Additionally, we can observe that during fine-tuning on the Ukrainian dataset, the model did not lose its ability to recognize and work well with the English language.
Model inference
Figures 10–12 present the results of the model’s inference.



Summary
The result of the research is a software system for visual question answering, which includes a server with a trained neural network responsible for predicting answers to questions, as well as a website that provides convenient functionality for interaction between users and the model. The created software system offers the capability to familiarize oneself with artificial intelligence algorithms, interact with the researcher, and view and modify the project’s source code (links below).
Code
Follow-up articles
To delve deeper into the topic of VQA and explore its application using RNN, we will be publishing a further article. In the next installment, it will be demonstrated how an RNN can provide a sentence as the result of the inference, bringing us closer to more accurate and context-aware answers.
you might also like…
Face Recognition For Document Identification
Subject: Face recognitionData Science Areas: Computer Vision, Object Detection, Face Detection, Face RecognitionTools: Python, Dlib The Challenge Our clients approached... Read more
Data Imputation using Reverse ML
Abstract Imputation fixes broken data. Methods are from making it constant mean to clustering, regression and generative networks. What if... Read more