

Let’s Talk about Pitfalls and the Best Route to Choose NLP model.
Why is it so important to quickly evaluate the accuracy of an ML model?
While building models for NLP on our own and from scratch, we were constantly communicating with our clients and asking ourselves “Is there any faster & simpler way for NLP tasks, where no specific knowledge or experience in (NLP) natural language processing is required?”
You will ask “why?”. The answer would be – because:
- Time is money.
- We need a baseline for the optimization of our models.
So we decided to test some of the recent tools on the market, developed by well-known companies, so called “BIG PLAYERS” in Automated (NLP) Natural Language Processing:
Google Cloud (https://cloud.google.com/automl)
Amazon Comprehend (https://aws.amazon.com/comprehend/)
Azure ML (https://studio.azureml.net/)
IBM Cloud (https://www.ibm.com/watson/)
How to evaluate all those Automated NLP tools?
The answer was quick and simple about Automated NLP:
- The task should be realistic.
- The evaluation should be independent.
- The process should not be very time- and resource-consuming.
We did what many data scientists would do, looking for a task to solve – went to kaggle.com and voila, we found https://www.kaggle.com/c/nlp-getting-started, which fit almost all of our criteria:
- Real-life (tweets)
- Independent evaluation (by submitting the result to kaggle)
- Small dataset (7K records) and the names of “BIG PLAYERS” promised – the process seemed to be simple & fast
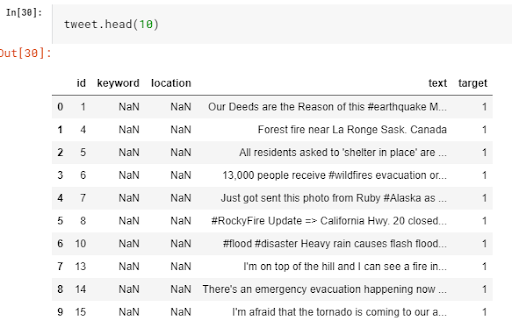
Dataset: Disaster Tweets

Many disaster relief organizations and news agencies monitor Twitter or at least plan to do it, because it’s one of the important communication channels in times of emergency.
The problem is how to classify tweets, how to process their meaning to determine whether the tweet is about a real disaster or not.
There are only two useful columns in our dataset – the tweet itself and its binary label (showing whether the tweet is relevant to a disaster or not). The dataset consists of 10,000 tweets, that were manually classified.
So our plan was the following:
- Take this dataset.
- Train the model using a built-in “Text Classification” feature.
- Then test it, by means of submitting to kaggle.
Google Cloud AutoML
The prep work was quite fast and simple:
- Create an account (although you probably already have one ) on Google Cloud Platform.
- Activate relevant Google services in the kaggle notebook (using the add-on menu).
- Run the jupyter notebook to train & test the model.
Thanks to https://www.kaggle.com/yufengg/automl-getting-started-notebook we had the backbone for our code:
Here you go, the only thing left is to wait for the results of model training by running the jupyter notebook.
The result of just 1 hour of prep work + 4 hours of training was quite empowering : 0.80061 by KAGGLE score.
Takeaways from Google Cloud AutoML Testing:
- Not so bad for just copying & pasting (if you don’t know the other results).
- No idea about the algorithm, only hints about BERT.
- Like all Google products – simplified and reliable.
Amazon Comprehend

The prep work was a little bit more confusing, but Amazon Comprehend FAQs helped a lot.
A typical list for manual data preprocessing consists of:
- Enclosing all the fields by quotes ( “ )
- Encoding in UTF-8
- Unpacking (because the results are in a .gz file)
- Converting the results from .json to .csv
Now it looks more user-oriented, almost like “choose-and-click“:
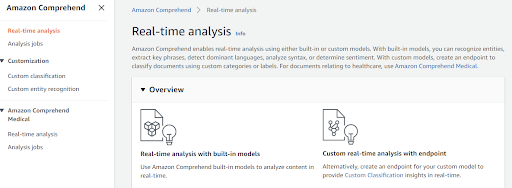
- Create a S3 bucket (the model works only on Amazon resources)
- Create a Classifier
- Create an Analysis job (for running the trained model)
- Run the Analysis job (run the trained model)
We were surprised by the speed. The training took about 15 minutes, which would be amazing if not for the 0.75051 by KAGGLE score.
Takeaways from Amazon Comprehend Testing:
- Amazon’s rich ecosystem, user-friendly interface
- For our experiment – special menu items, metrics
- Really fast, at least for our experiment
Microsoft Power Apps & Azure ML Studio

For the first hour of testing it, we thought – finally there’s a tool, where everything would be smooth. At the beginning, it seemed clear and transparent:
- No obligatory enclosing
- No converting from .json to .csv
- Excel-style “data-preprocessing”, etc.
But when the process of configuring the training model took more than 2 hours, because of some inexplicable errors – we decided to stop experimenting with it.
Takeaways from Microsoft Azure Testing:
- To solve a simple text classification task we had to build a full data science pipeline in a built-in IDE (with blocks for typical steps in data science: data preprocessing, building, training, testing, deploying models using the “drag-n-drop” technique).
- APIs for almost any databases and any apps.
- But errors during the model training make us feel like rookies in data science projects.
IBM Watson

Again, smooth and clear:
- Creating an account (free for our model)
- Choosing the necessary model (“Text Classification”)
- Feeding a testing dataset to the model
- Training the model – took about 4 hours
(which was not so surprising after the Google option) - Checking the model – by one example
(as in the previous tools)
Then, the process became a little bit more complex. For more than one example to the model, we had to use the API for Python and saved credentials of the model (we did it by means of the Python code from FAQ’s)

“Old-School” NLP Style
We would not be real data scientists, if we didn’t try the traditional style…
A classic recipe for our Text Classification case was as follows
Ingredients: Jupyter notebook, standard libraries: numpy, pandas, sklearn and “the cherry on top” –Google’s algorithm for Natural Language Processing – BERT.
Thanks to very good kernels:
we have a transparent path for building and training BERT models.
As usual, some data-cleaning work:


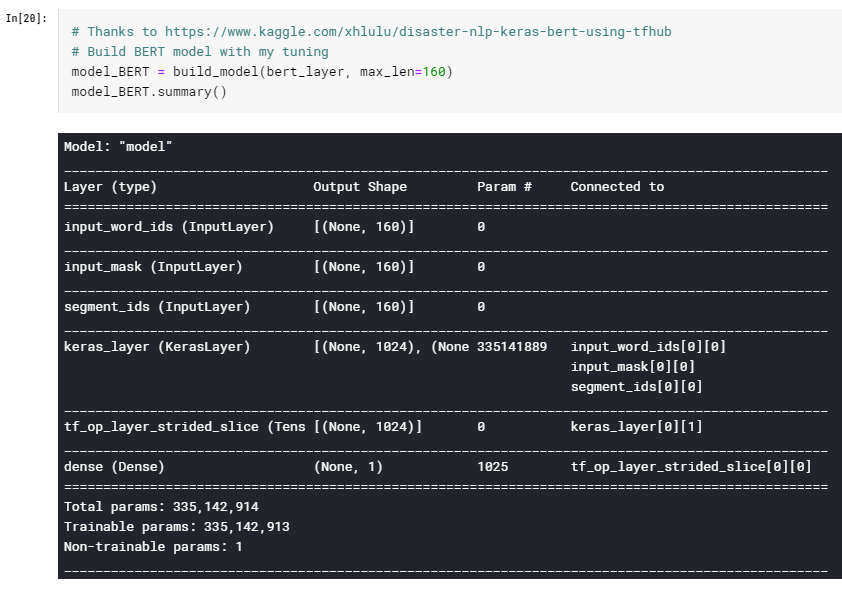
Then building the BERT model:
Training the BERT model:
(took about 20 minutes)
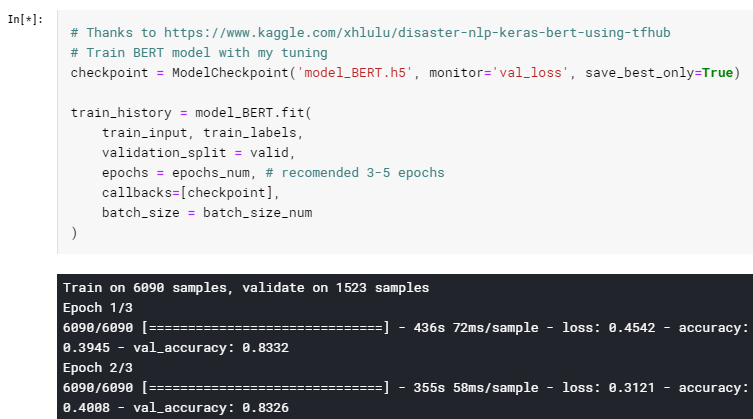
Finally, here are the results of our “old-school” method: 0.82413 by KAGGLE scoring.
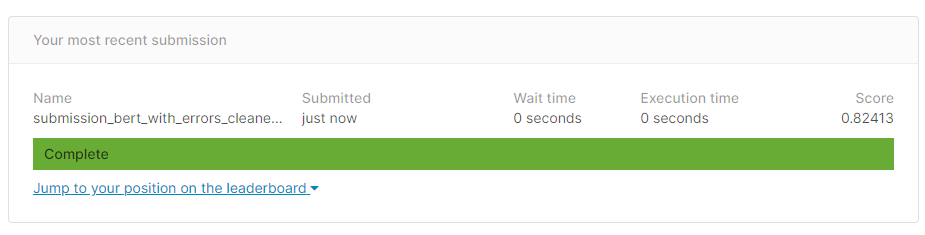
Taking into account the errors, we squeezed a little bit more out of it – 0.83128 by KAGGLE score.

Takeaways from the “Old-School” Style:
- cleaning job is a “must-have”
(otherwise, the final score reduces dramatically…) - errors in the training dataset
(Thanks to https://www.kaggle.com/wrrosa/keras-bert-using-tfhub-modified-train-data – the author of this kernel read tweets in the training data and figured out that some of them have errors.)
Summary of Results
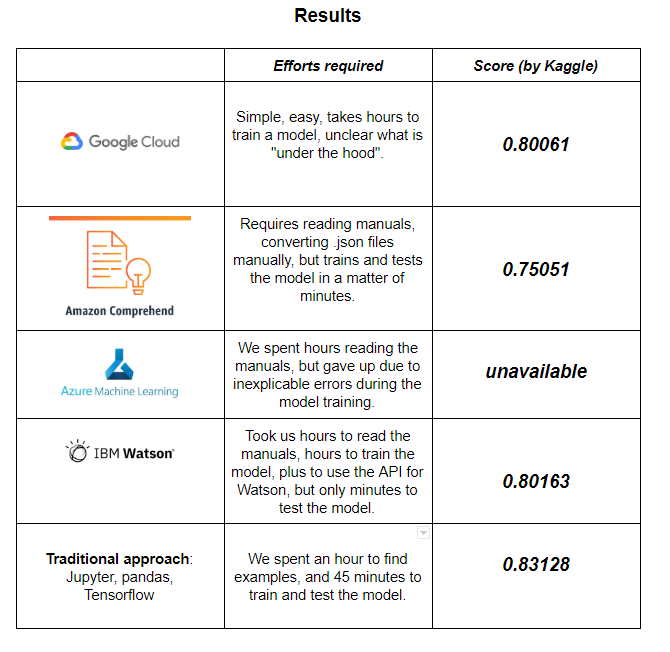
Takeaways from the “BIG-PLAYERS NLP or Automated NLP” List
All tools from the “BIG PLAYERS” have:
PRO-s:
- They are multi-language (but we tested them only for English).
- The training and evaluation of the models is completely automated and no machine learning knowledge is required.
- Every tool has a built-in test for ONE example after training the model
(we can send it a request and receive the predicted value). - The tools have their own IDEs for data-preprocessing with built-in jupyter, python support.
- Convenient and flexible with their own APIs, IDEs.
CON-s:
- All tools have their own requirements for data training, which differ a little bit, in terms of the minimal number of rows, maximum number of records (for free- computing) and classes, maximum total length of a text value, balanced use of tags, etc.
- Lack of access to the models
(The models cannot be tuned to a specific task or dataset). - They all have their own limitations
(like: training items, labels, length of a label name, training items per label, etc.)
They contain only hints about the used models. - They use their own storages for datasets.
- Price: they charge based on the amount of text processed and the processing time.
Conclusion
So what are the pitfalls and the best route to choose?
Automated NLP can speed up the entire process – from data cleaning to deployment – and even help achieve satisfactory results within the limited time and with limited resources.
But in the modern world, where:
- The tenth of a percent in model’s accuracy can crucially affect your competitiveness
- Real-life tasks are much more complicated than the ones offered by classic NLP Automated NLP wouldn’t be the right choice.
I want to thank my colleagues Andy Bosyi Mykola Kozlenko, Alex Simkiv, Volodymyr Sendetskyi for their discussions and helpful tips as well as the entire (MindCraft.ai: Data Science Development company | ML & AI Company) team for their constant support.
Author:
Andrii Grytsyna, Data Scientist MindCraft.ai
Information Technology & Data Science
you might also like…

OCR Challenges – Insights from MindCraft at ODSC Discussion
On January 28th, our team participated in the Open Data Science Conference (ODSC) MeetUp. Andy Bosyi, Co-founder of Mindcraft, gave... Read more

Differentiable Programming: A Paradigm Shift
Svitla Smart Talk recently hosted a compelling video conference featuring Andy Bosyi, Co-founder of MindCraft, delving into the emerging field... Read more