

Short info for the current state of NLP technologies
Introduction to NER
At the moment all available NER approaches fall into two big categories: useful for applied NLP problems and oriented for primarily scientific development. Much work is in progress to close the gap but it is still wide especially after so-called BERT explosion. An excellent example of a library for applied NLP is spaCy covered in depth later. Google has open-sourced several modern language models making them available with TF 2.0 and TF hub pre-trained models library. PyTorch also had the same type of option PyTorch Hub. Both give us the opportunity to use deep models pre-trained on a huge text corpus but with limited access to internals. At the moment top results are from BERT, GPT-2, and (the very recent) XLNet architectures. The most popular NLP leaderboards are currently dominated by Transformer-based models. BERT (Devlin, Chang, Lee, & Toutanova, 2019) received the best paper award at NAACL 2019 after months of holding SOTA on many leaderboards. Now the hot topic is XLNet (Yang et al., 2019) that is said to overtake BERT on GLUE and some other benchmarks. Other Transformers include GPT-2 (Radford et al., 2019), ERNIE (Zhang et al., 2019). The problem we’re starting to face is that these models are HUGE. While the source code is available, in reality, it is beyond the means of an average lab to reproduce these results or to produce anything comparable. For instance, XLNet is trained on 32B tokens, and the price of using 500 TPUs for 2 days is over $250,000. Even fine-tuning this model is getting expensive
spaCy
Introduction
spaCy – free, open-source library for advanced Natural Language Processing (NLP) in Python. Among various features it has, (text tokenization, POS tagging, linguistic annotations, etc.) it is also capable of solving the NER tagging task.
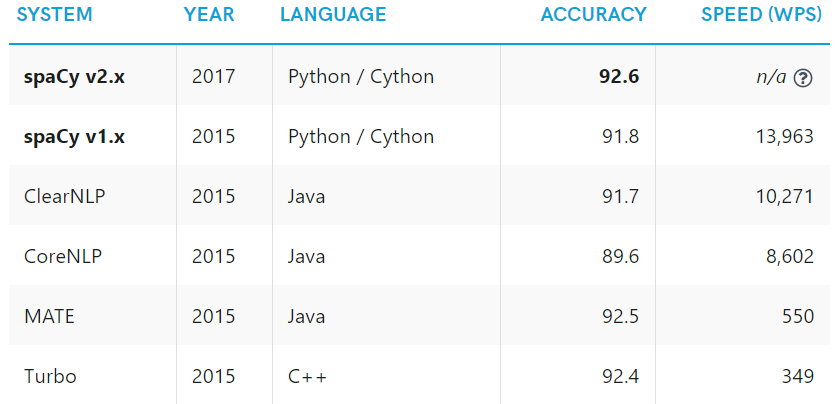
Two peer-reviewed papers in 2015 confirmed that spaCy offers the fastest syntactic parser in the world and that its accuracy is within 1% of the best available. The few systems that are more accurate are 20× slower or more.
NER pipeline
There are few parts of spaCy, that take part in its NER tagging process. Few of them are shared among other spaCy features.
The first part of spaCy is tokenizer: given text, tokenizer splits it into tokens. This is done by applying rules specific to each language. For example, punctuation at the end of a sentence should be split off – whereas “U.K.” should remain one token. There are base rules, that are applied to all languages. But, those ones, that are specific for separate languages, are hardcoded in corresponding files.
Next, after a text is tokenized, each token is turned into its hash value, then this hash value is used for generating token embedding – context-independent vectors of values. This is done with statistical pre-trained models. These models are trained on great amounts of texts, available on the Internet. spaCy has few models available, trained on different types of texts.

After each token has been embedded, a sequence of those embeddings, which represent a whole sentence, is passed to a CNN, which embeds this sequence into a context-sensitive sentence matrix.

This operation recalculates token’s embedding with now including token context.
Having this matrix, each new token vector is passed to specific attention model as well as a few nearest ones which predict exact token tags.
Available models
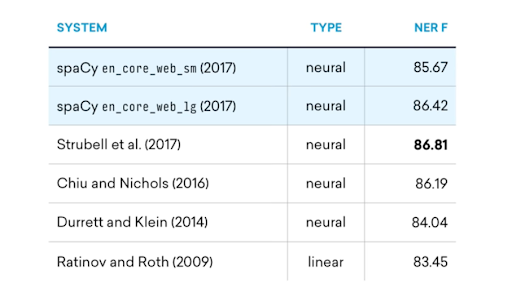
There are few models currently available at spaCy. As mentioned above, those models differ in texts they were trained on. The other notable differences in those models are their size and performance. To make them compact and fast, spaCy’s small models don’t ship with word vectors, and only include context-sensitive tensors. If your application will benefit from a large vocabulary, big models can be used: they usually include over 1 million unique word vectors embeddings. As for the NER task, the bigger model performs only 1-2% better than the smaller one (see table below), since NER task despite uses those embeddings, mostly relies on final classification layer and appears to be a harder problem to solve then POS tagging.
The image below shows the performance on the NER task of two English spaCy models compared to a few other ones. As one can see, the big model performs only ~1% better, than the smaller one.
Here is a list of currently available models:
| German | de | 2 models |
| Greek | el | 2 models |
| English | en | 4 models |
| Spanish | es | 2 models |
| French | fr | 2 models |
| Italian | it | 1 model |
| Dutch | nl | 1 model |
| Portuguese | pt | 1 model |
| Multi-language | xx | 1 model |
Training custom models
Despite showing relatively high results within low resource usages, spaCy still does not perform perfectly. In order to improve the model’s performance on a more specific than general NER task, a model needs to be trained. This can be done with built-in functions and CLI commands.
Note, that model is context-sensitive. So, if a model is trained on Wikipedia articles, where there are very few sentences from the first person, it will perform badly on Twitter posts, or model trained on novel books will perform badly on legal texts, etc.
At August 3, 2019 spaCy released integration wrapper spacy-pytorch-transformers that allows access to pre-trained transformer library Pytorch-transformers that is covered in more detail later.
Kashgary
Kashgari ⚙️ An NLP transfer learning library built on top of tf.keras that allows you to easily build state-of-art models for NER, POS tagging, and text classification tasks.
Overview
Kashgari is a simple and powerful NLP Transfer learning framework, build a state-of-art model in 5 minutes for named entity recognition (NER), part-of-speech tagging (PoS), and text classification tasks.
- Human-friendly. Kashgari’s code is straightforward, well documented and tested, which makes it very easy to understand and modify.
- Powerful and simple. Kashgari allows you to apply state-of-the-art natural language processing (NLP) models to your text, such as named entity recognition (NER), part-of-speech tagging (PoS) and classification.
- Built-in transfer learning. Kashgari built-in pre-trained BERT and Word2vec embedding models, which makes it very simple to transfer learning to train your model.
- Fully scalable. Kashgari provide a simple, fast, and scalable environment for fast experimentation, train your models and experiment with new approaches using different embeddings and model structure.
- Production Ready. Kashgari could export model with SavedModel format for tensorflow serving, you could directly deploy it on cloud.
Performance
|
Task |
Language |
Dataset |
Score |
Detail |
|
Named Entity Recognition |
Chinese |
People’s Daily Ner Corpus |
94.46(F1) |
PyTorch-Transformers
is a library of state-of-the-art pre-trained models for Natural Language Processing (NLP). At the moment only “scientific” part of the library is available. Applied (aka developer) part is yet to be released as of 2019.07.25 This language models prove to be useful for NER tasks but usually need extensive fine-tuning for target language distribution. This approach is effective but very computationally expensive. For example BERT variation with 12 layers to deliver better results was tuned using 60B text corpus.
The library currently contains PyTorch implementations, pre-trained model weights, usage scripts and conversion utilities for the following models:
- BERT (from Google) released with the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
- GPT (from OpenAI) released with the paper Improving Language Understanding by Generative Pre-Training by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
- GPT-2 (from OpenAI) released with the paper Language Models are Unsupervised Multitask Learners by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.
- Transformer-XL (from Google/CMU) released with the paper Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
- XLNet (from Google/CMU) released with the paper XLNet: Generalized Autoregressive Pretraining for Language Understanding by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
- XLM (from Facebook) released together with the paper Cross-lingual Language Model Pretraining by Guillaume Lample and Alexis Conneau.
How to get tuned
For spaCy free online course was released. It is a good point to start with if you intend to start with the library. spaCy free interactive course and concept list.
For general purpose NLP education check fast.ai A Code-First Introduction to Natural Language Processing
Contact us if you have for personal questions and if you have needs in AI, or you need to set up a Data Science consulting team
team@mind.local
Read also : Differentiable Programming – Inverse Graphics AutoEncoder
you might also like…

Data Science Made Simple: MindCraft’s TechTalk
MindCraft, with the support of ITEAHub, successfully hosted its highly anticipated TechTalk, “Data Science: Complicated Stuff in Simple Words,” on... Read more

Artificial Intelligence In E-commerce
Leveraging AI for e-commerce This article outlines the possible ways of how e-commerce businesses (both the existing and the new... Read more