

After reading this article you will:
- learn how to select the right Machine Learning solution that will truly bring value to your business and will ensure great ROI
- find out what to be aware of when starting to implement Machine Learning solution & AI for business
- understand the practical steps of working with business data and starting a Machine Learning solution
Who will benefit from this knowledge:
- Big enterprises planning to leverage AI & Machine Learning solution for their business or only exploring the options
- Startups, companies at the beginning of their business journey, with limited resources
We defined a few key directions to explore, which will help you efficiently implement Data Science projects:
- How to select the right ML & AI project
- The Capabilities of AI/ML
- How to Start a Machine Learning solution in Your Company
- Working with Data and Datasets for Machine Learning solution
- What do You Need Data for?
- Practical Example: How it Works in Practice
How to select the right AI & Machine Learning solution (What should you start with?)
Before you select an AI project which you and your Data Science team will be working on, you need to understand the 3 golden rules which should shape your approach:
- Be fully aware of the capabilities of AI & Machine Learning solution and their limits
- Be deeply familiar with the needs of your business
- Know what kind of data you’ll be working with and how long the realization will take
On the picture below you can see a tutorial on how to select the right project for your business taking into account its peculiarities. For this, will use the well-known “Hedgehog Concept”, which has been described in detail in the book Good to Great by Jim Collin
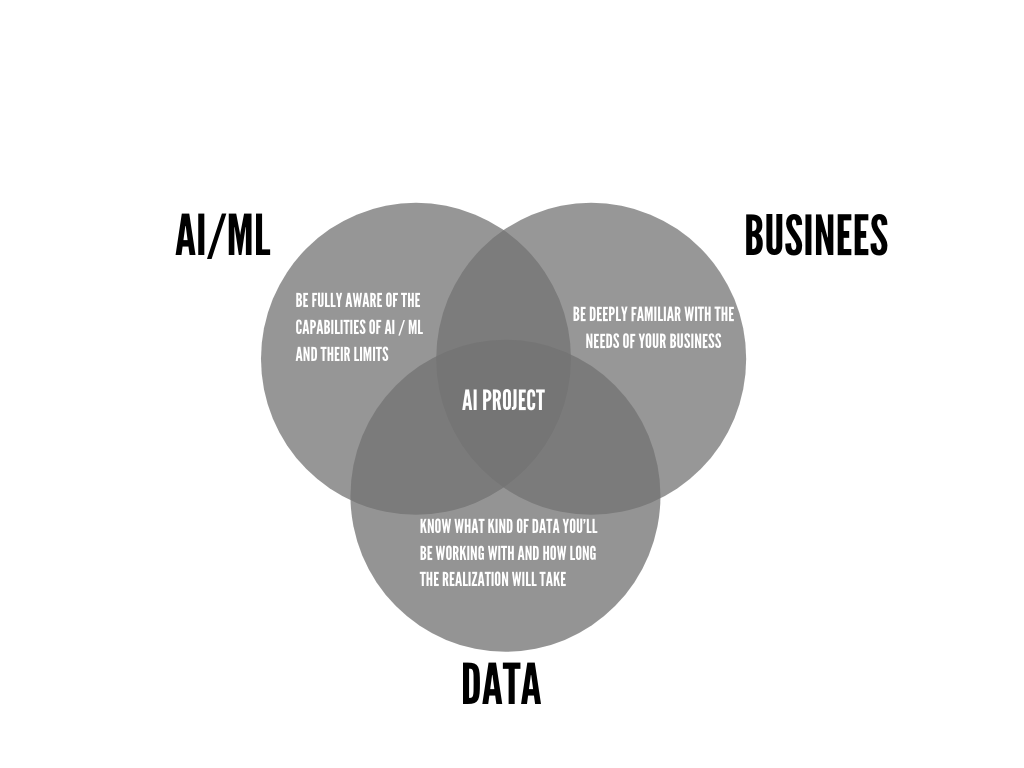
As you can see, if we combine these two circles, in the middle we’ll get a project which is the most likely to bring you value and good ROI. Now let’s get into the details of this concept.
The Capabilities of AI & Machine Learning solution
Pay attention to the fact, that most of the things you heard about Artificial Intelligence are positive and optimistic, as successful projects are widely featured in the media and discussed online. That is why, what most people think about AI is a distorted opinion, not totally corresponding to reality. Unsuccessful projects are not exactly the hot topic in business circles, but this is what data scientists love to discuss, as these cases are a source of invaluable information and knowledge.
Good data scientists always keep an eye on both successful and failing projects. At the conferences, we often discuss our personal researches and experiments, what worked and what didn’t, providing food for thought for both our colleagues and our customers.
So what is ML&AI capable of? Modern approaches to Machine Learning and Artificial Intelligence allow automating routine tasks of humans. In other words, modern self-taught systems can do the same simple things that humans can (information classification, recognition, fault detection, simple actions that usually don’t take much time) At the same time, AI is not capable of critical thinking, imagination, and activities which require some background knowledge. The reason is that in Data Science everything is built upon statistics and numbers, not much fantasizing is allowed.
Start with the project most likely to succeed
We believe that it’s important to use AI specifically for working process automation, without excluding the human factor. If you’re only starting your journey into AI/ML, you should start with the project most likely to succeed, and with the duration no longer than 1 year. Here’s why:
- It will give you a chance to understand how you should develop a project involving Artificial Intelligence and how R&D works
- You will quickly get the first results, which will help you in your work and in further steps
- It will be easier to keep an eye on the needs of your particular business, since in the modern world the way of doing business changes every day, increasing the risks of launching a product with no real potential
One of the most important aspects is that an Artificial Intelligence model does not allow for compromises, as opposed to a real human mind.
How to Start a Machine Learning solution in Your Company
Do not undertake global tasks at once. Many companies want to do everything at once and of global importance. We have spoken with CEOs of the companies willing to automate all departments at once in 2-years time. With no previous experience in AI, they rely only on the development strategy. Here’s how we think you should start:
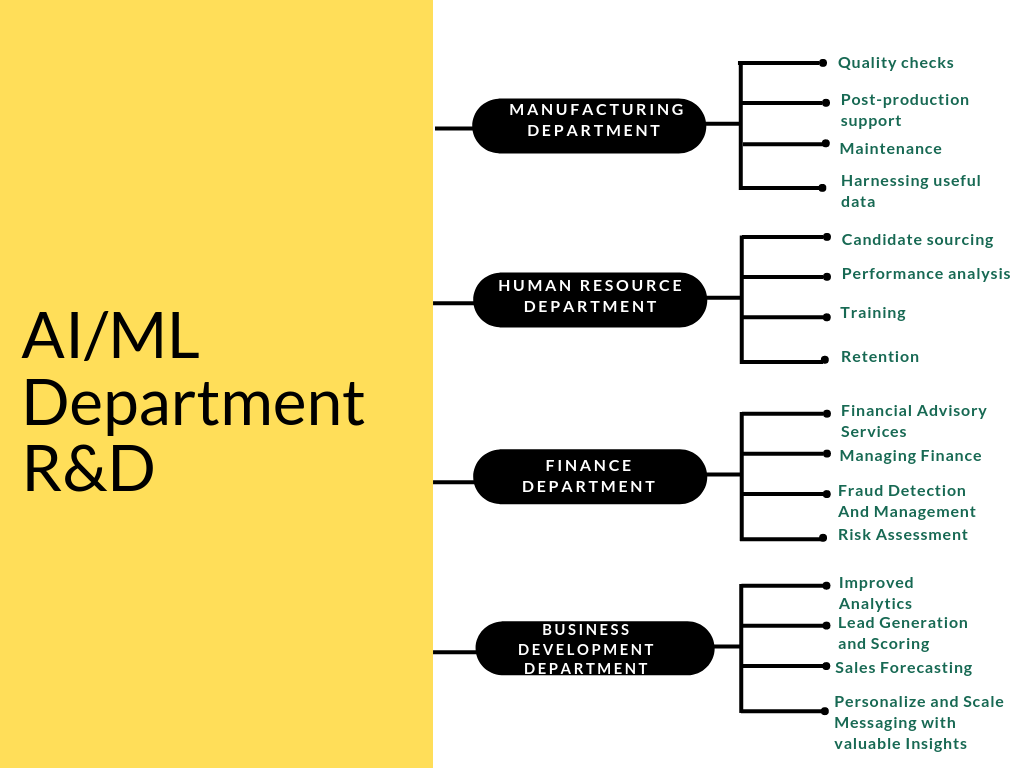
Every company consists of a few departments, each of which has its own data. We strongly recommend starting automating these departments gradually, after getting to know their needs and priorities. Data scientists can advise you on how you can improve their existing processes, if there are any helpful existing solutions, which data you’ll need and of what quality. For example:
- Manufacturing – a system which will detect product defects on its own, with the help of Computer Vision and Object Detection.
- Business development department – a system that can help generate a personalized offering for each client, based on their tastes, region, purchase history, etc.
- Finance department – a system helping to detect, classify and sort documents
- HR department – employee analytics solution, helping to split the employees into categories and estimate possible risk factors (like the one by Ginni Rometty, CEO at IBM); or create a system for quality control based on your corporate rules, there are many options.
Working with Data and Datasets for AI & Machine Learning solution
The amount of data is directly connected with the training. The more data you have, the higher the accuracy and the quality of your result. But what should you do if there’s not enough data? You’ve got 4 options:
- Data generation. You can generate the needed data, but keep in mind that they are not native data, and when you’ll have the real datasets, the system will work with them in a different way, you might need to make corrections.
- Ready datasets. Now you can find a lot of data on the internet. It is highly likely that the task you’re trying to solve has already been accomplished by somebody else and so you could ask for their data. You can also purchase ready datasets you need, it depends on the size of your project.
- Augmentation method. There are a few tricks to fool the system, expand the dataset, turn the page upside down, duplicate it or take a different angle. It will only add a bit, but it could be pretty handy.
- Own data generation. The data science team can provide means for the most effective data labeling aka active learning. Sometimes it’s better if you wait for 1-6 months and work with your own data, than with someone else’s borrowed or purchased.
You should always monitor the data purity!
Let’s say you wish to have a system that can recognize traffic signs on a picture. You take a photo, label the road signs on it so that the system can memorize them. But imagine you make a mistake and accidentally label a sign on the store, doing so 100 – 1000 times or you make any other mistake. The system starts perceiving the store sign as a road sign and it affects the result. So your approach to the data purity and labeling should be more than scrupulous.
In most cases, we at MindCraft make an individual tutorial for the clients explaining the labeling process: things to pay attention to and how to label correctly.
Also, there’s a number of methods which help to clear the data automatically. If you’d like to know what these are – contact us via email and we’ll tell you more about them.
What do You Need Data for?
Data are the information that Artificial Intelligence has yet to process, learn and then on the basis of this information, it will be able to work further. You “feed” the data to a Machine Learning model, this way showing what’s expected of it.
For example, if you want your system to recognize dogs and cats, first you have to show to the system what’s a “cat” and what a “dog” means. You have to show it at least a few thousands of pictures of cats and dogs so that in the future the system will be able to detect the cat among dogs on its own. The data needed for the engine to work are called a Dataset.
Data labeling process
How can you show to the system what is a cat having a picture of a cat and a dog? This process is called data labeling (marking). In this case, you manually label each photo, saying whether it’s a cat or a dog. In practice, it looks in the following way: 1 or 0 (where 1 is a YES and 0 is a NO). If labeling thousands of photos is too long and tedious for you (which it is for anybody, as a rule), there are a few other ways:
- Ready and labeled datasets on the internet that you can find and download.
- Many companies nowadays provide labeling outsourcing services. On average, it costs around $0.25 – $4 per file. However, if you have lots of data, the costs can skyrocket
- Interesting approaches like the one we described here. This approach helps to save on the labeling. Briefly, if you have 10,000 items of data that need labeling, using this approach you’ll have to label only 1,000, and the system will do the rest automatically, saving time and money.
Labeled datasets are needed for the period of training when the system makes its first steps. After the training period is over, it can process the info on its own and you’ll need raw, non-labeled data. Your task at this stage is to make sure the model receives those on a regular basis.
We’ll describe two of the most widespread training methods, but there are many more.
Supervised Learning
Most Machine Learning projects are based on Supervised Learning, a learning process from A to B. It means that you give an A to the system (input data, labeled) and B, what you want to achieve as a result, what the system has to learn. In other words, you determine the frames within which it works. This method is commonly used for the automation of manual processes, where there’s A and B (A is the data people work with and B is what they do with it, how they sort it, recognize it, detect defects, etc.)
Unsupervised Learning
The other method is currently only developing, but we strongly believe that it’s where the future lies. It’s called Unsupervised Learning and here’s how it works. We give input to the system, and sometimes the goal, but we don’t say how to reach it. The system analyzes the data looking for similarities, unites those into clusters. Sometimes a system like that can give you such deep insights about your data that it can turn into a huge success for your business. However weakly developed, we believe that this method can become the next big thing.
Practical Example: How it Works
Here’s how the whole process looks like on a real case:
The Client is a company which has its own call center for customer support. The problem they are trying to solve with a Machine Learning engine is maintaining the high quality of communication between phone operators and customers by means of monitoring operators’ work.
There are around 200 phone operators in this call center, one employee receives on average 3500 calls per month. There’s a back office of 20 people, whose main task is to listen to 10 random calls of each operator per month and evaluate their work, thus affecting the salaries.
It means that from 3500 calls only 10 are really evaluated. That is why the company is trying to figure out how to automate the process and find an alternative for unreliable random checks.
The solution of Exapmle
This client has millions of recorded calls in the database. Based on that, we can try and build a system which will recognize the voice and words. It’s a typical Speech Recognition task. Then, we have to write down a list of words that the operators are not allowed to say. As soon as the system hears a word from the list, it will send the call recording to the back office. This way the back office will have to work only with the calls which got into the risk group, improving their efficiency and the overall service quality.
To complicate the task, we can work with intents, teach the system how to recognize the topic of each conversation. This is how we can check whether phone operators always give their customers true information.
What the engine is absolutely not capable of is recognizing the emotions of the two participants of the conversation, as this is something that even humans are unable to determine correctly.
On the input:
- Data (Hundreds of thousands of recorded calls)
- A list of words and rules operators cannot use while talking with the customers
On the output:
- All calls are analyzed and divided into good and bad, the back office gets alerts if violations occur
So it’s a simple supervised learning process from the input to the output. We use examples to teach the system what the operators should and shouldn’t do. The system repeats it and starts analyzing the new data by itself.
Manual Work: AI Engine:
Calls per month: 3500 Calls per month: 3500
Processed Calls: 10 Processed Calls: 3500
Method: Random Checks Method: Alerts System
Summary
If you combine deep knowledge of your business needs with a thorough understanding of what Machine Learning can and cannot do, you’ll be able to automate many of your routine processes, redirecting your efforts and resources into more important and strategic zones. Start your AI automatization plan from smaller things. First, get familiar with the AI setup process. Then, receive at least a basic system automatization experience. If you have questions or need a consultation don’t hesitate, reach us at team@mind.local We are certain that one day, sooner or later, all companies will leverage the enormous potential of Artificial Intelligence.
Author:
Nazar Savchenko, OD at MindCraft
Information Technology & Data Science
you might also like…

MindCraft at KSE: AI/ML Insights
MindCraft, is proud to announce its participation in the Kyiv School of Economics (KSE) community by delivering a specialized lecture... Read more

Data Science Made Simple: MindCraft’s TechTalk
MindCraft, with the support of ITEAHub, successfully hosted its highly anticipated TechTalk, “Data Science: Complicated Stuff in Simple Words,” on... Read more