

How LLMs Can Reinforce the Existing Topic Modeling Pipelines
Introduction
The topic modeling task originated a long time ago. The main idea is to group the collection of documents (of any type) into several specific clusters, aka topics. This article focuses on analyzing the big dataset of documents utilizing classic ML & modern LLM models.
In the practical part, we will utilize the BERTopic framework which provides a modular way to do the topic modeling task.

Source: Image generated by the author using AI (DALL·E 3)
Brief history
For a long time, the best solutions in this field were LSA (matrix decomposition-based approach that obtains semantic relationships based on the Singular Value Decomposition), PLSA (probabilistic LSA that assumes we have certain probability distributions modeling documents → topics and topics → words relations), LDA (a refined version of the PLSA that uses Dirichlet priors for generalization & efficiency), and PAM (extends LDA by allowing topics hierarchy, that is modeled using the Direct Asyclic Graph).
Above are listed the most widely known algorithms, but there exists much more of them.
In addition, many people utilized the embeddings (mostly based on the transformer’s models) based clustering techniques to obtain clusters that could further be classified as one of the topics. Below is a rough overview of the topic modeling process evolution through time.
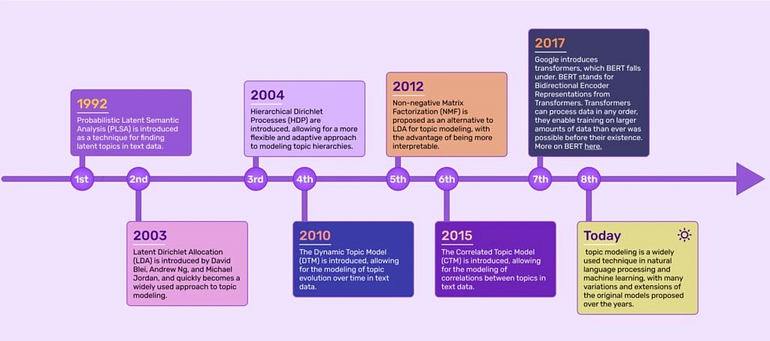
Source: https://theloops.io/more-on-topic-modeling-a-form-of-ai-for-customer-support/
Nowadays approach
In the modern world, we utilize frameworks for almost all of our tasks (of course, if you want to do them time-efficiently). Topic modeling is not an exception to this rule. From my research, there are 2 most popular frameworks for topic modeling:
- Gensim (provides efficient implementations of statistical approaches like LDA, LSA, etc.)
- BERTopic (provides efficient implementations for the embedding-based approaches).
We will dive into the BERTopic framework. The overall BERTopic model consists of 6 modules listed below. They are the base building blocks for our topic modeling solution.
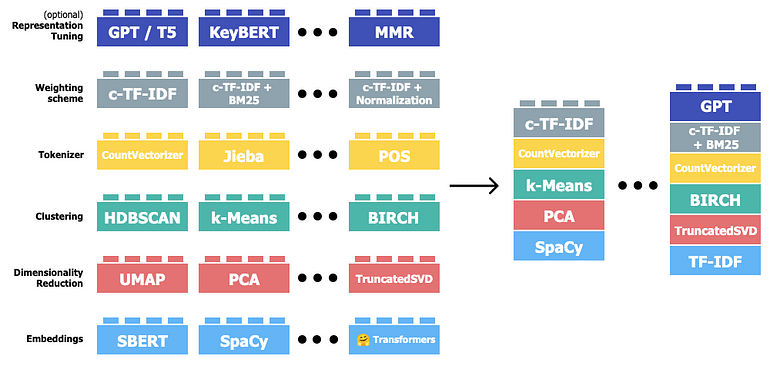
Source: https://maartengr.github.io/BERTopic/algorithm/algorithm.html#visual-overview
The representation tuning step is optional, but highly recommended. It can help to automatically obtain human-level topic names without direct human intervention (smth not possible several years ago).
For me, the original schema of modules was not clear, and that’s why I have redrawn the module’s schema more intuitively. I separated the topic modeling into 2 steps process:
- topic modeling on the surface (feature space)
- topic modeling in a natural language (n-gram space)
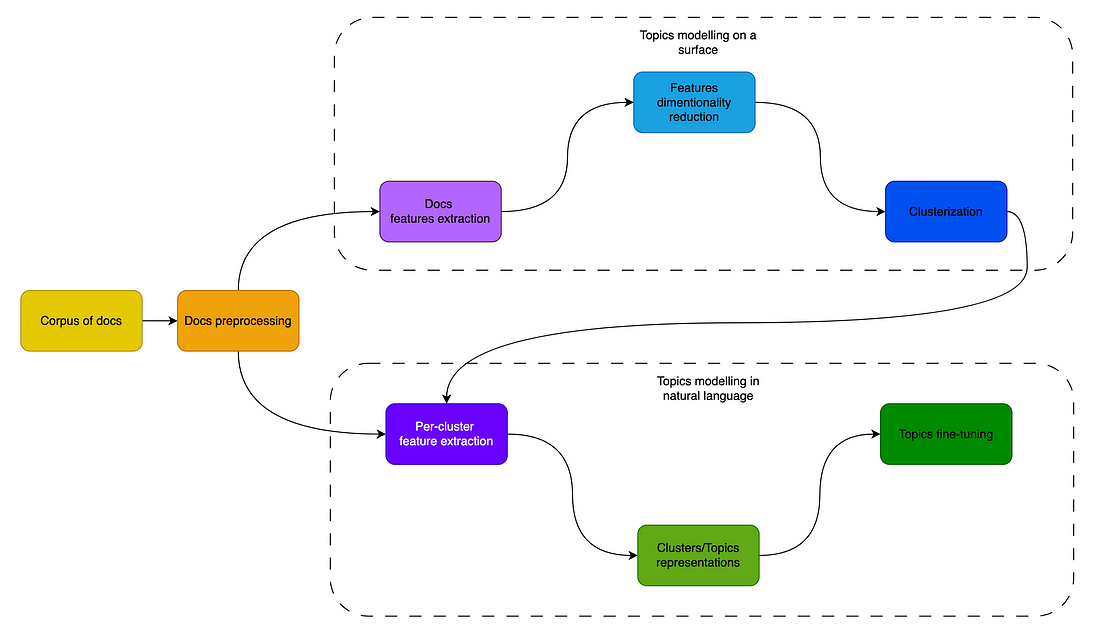
Source: Image created by the author
And for each of the modules, we have a lot of options to utilize. Below I have listed a brief overview of methods you can use. The grey blocks on the right represent some advanced features of the BERTopic that we won’t focus on, but I highly encourage you to read about them on the official BERTopic docs page (in case you implement a custom topic modeling solution).
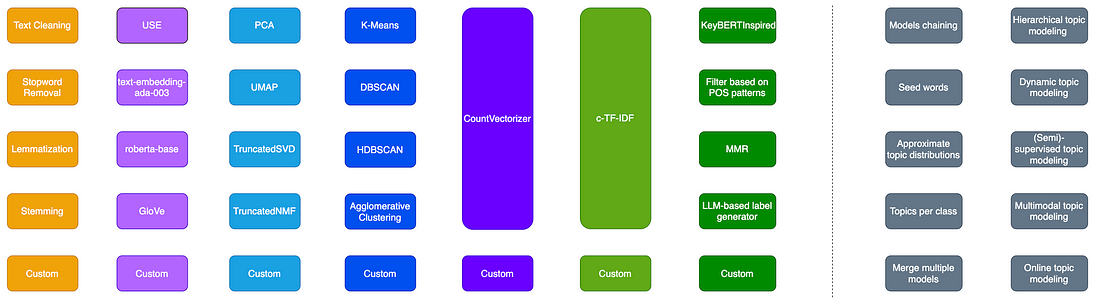
Source: Image created by the author
In addition, the topic modeling task is not always about finding new topics from scratch. There can be a predefined list of topics that your domain experts know about the field.
In case you would like to relatively fast label the dataset without directly reading all of the documents you can use the bulk labeling tools. I have recently encountered it and I guess it may be handy for certain use cases.

Source: bulk https://github.com/koaning/bulk
Practice
To apply the mentioned techniques we will utilize the 20newspapers dataset from the scikit-learn.
The 20 newsgroups dataset comprises around 18000 newsgroups posts on 20 topics split in two subsets: one for training (or development) and the other one for testing (or for performance evaluation). The split between the train and test set is based upon a messages posted before and after a specific date.
Below we will apply 3 different scenarios of the topic modeling task:
- manual topic modeling (labels exist for the whole dataset)
- zero-shot topic modeling (there are several initial topics we know exist)
- standard topic modeling (no labels and no initial topics)
Preprocessing
First, let’s start by loading the dataset:
In the further sections, we will utilize only the train part of the dataset to reduce the computations required. The dataset consists of 20 groups that are listed below:
Right now we should precalculate the embeddings for all the documents. This is a recommended technique to precalculate the embeddings one time instead of recalculating them several times during the model training/prediction.
Below are the utilities that will help us to truncate the documents and process them efficiently by combining several docs into a single batch.
Now let’s preprocess the documents:
As a result, we can see several documents being truncated to the 8192 tokens (current text-embedding-3-small limit):
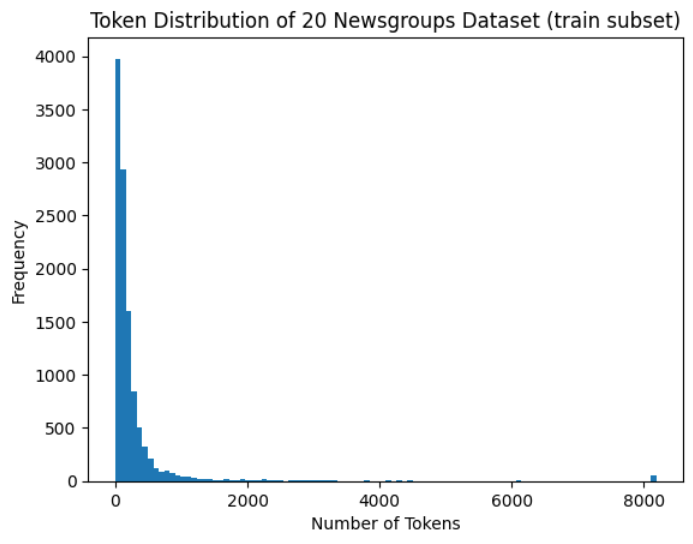
Source: Image created by the author
After that, we are ready to get the embeddings:
Now we are ready to apply these embeddings in further analysis.

Source: Image generated by the author using AI (DALL·E 3)
Manual topic modeling
This variation of topic modeling assumes that you already have the data and the respective labels for them.
Imagine that you already know the topics distribution in your data but you would like to understand the more detailed semantics inside them. That’s where manual topic modeling comes in handy.
For this we have to initialize the model:
Train/load the model:
Right after that, we can preview the list of the obtained topics:
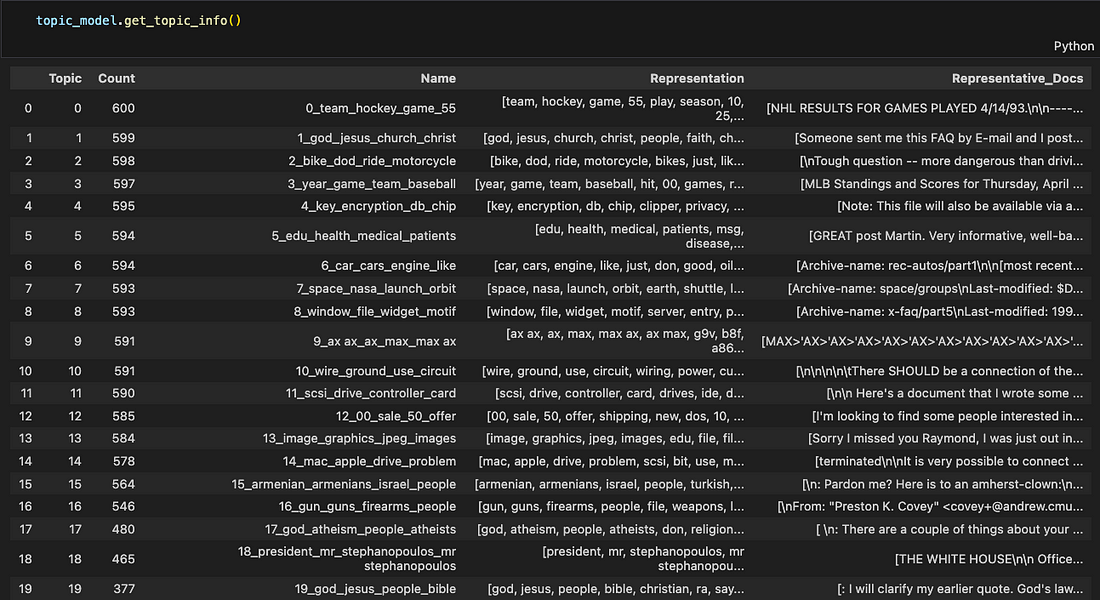
Source: Image created by the author
Now let’s map the topic IDs to the original names and visualize the keywords:
Below we may see the result of the fitted model, which provides the following distribution of keywords per topic:
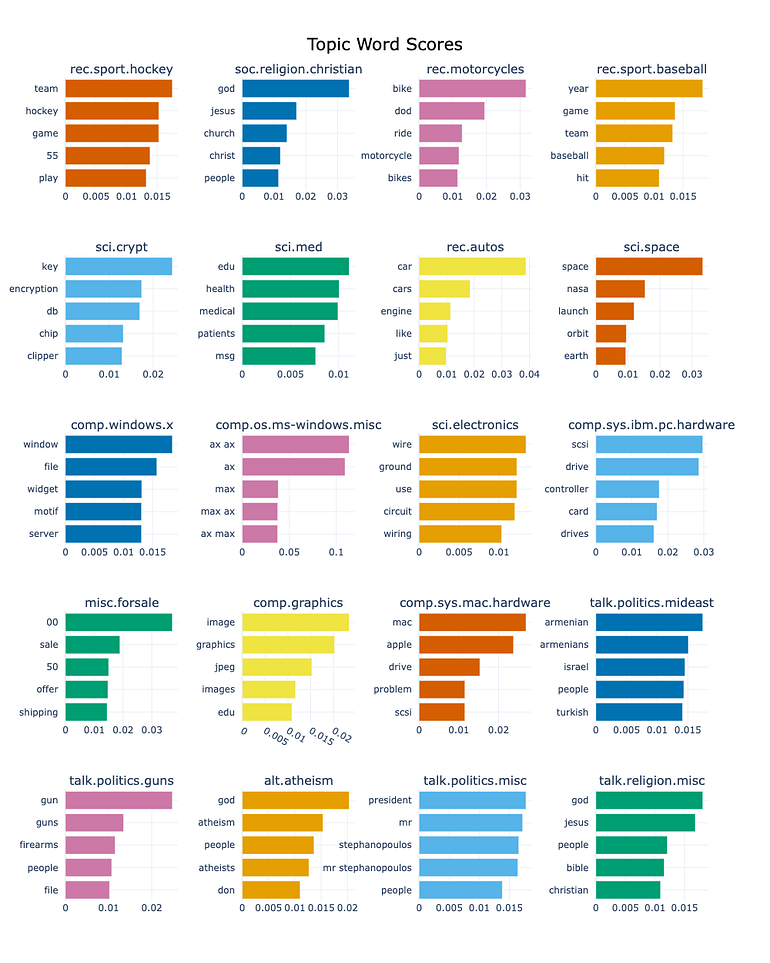
Source: Image created by the author
Topic modeling
Here we will review the use case when we have only the corpus of documents and don’t have a predefined list of topics.
We will start using the BERTopic model initialization. The parameters for most of the models are default.
After the definition, we should train/load the topic model:
Let’s take a look on the most popular topics extracted from the dataset:
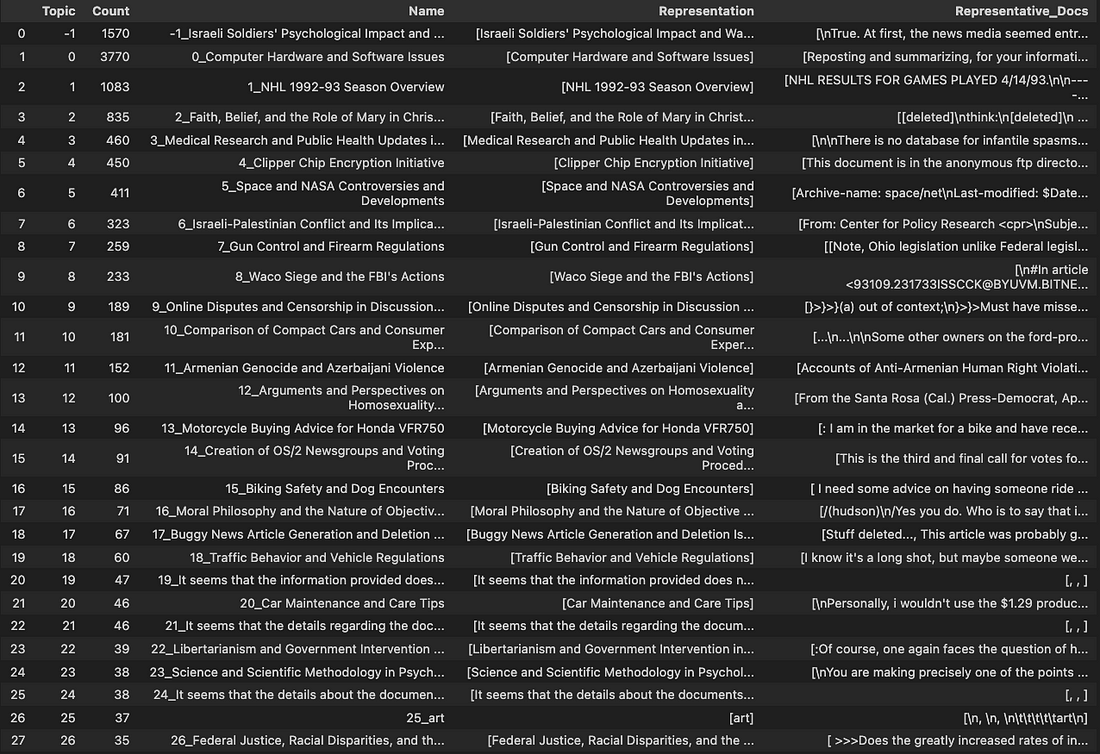
Source: Image created by the author
We see the reasonable topics obtained from the pipeline, meanwhile there are 1570 samples classified as topic -1. -1 topic means that these documents were considered outliers. In the real cases, this should be reduced as much as possible.
The data frame with topics is good, but we need more visuals to better understand the data. The similarity matrix can be your starting point for considering merging several topics into one combined
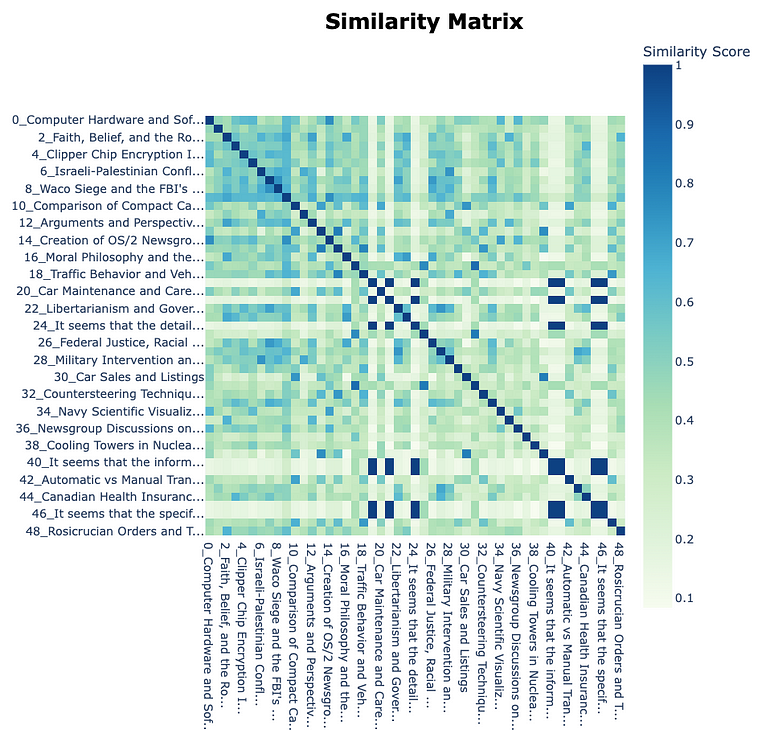
Source: Image created by the author
In case you had the initial labels but didn’t use them for the topic modeling, you can plot the distribution of detected topics to the 20 predefined topics.
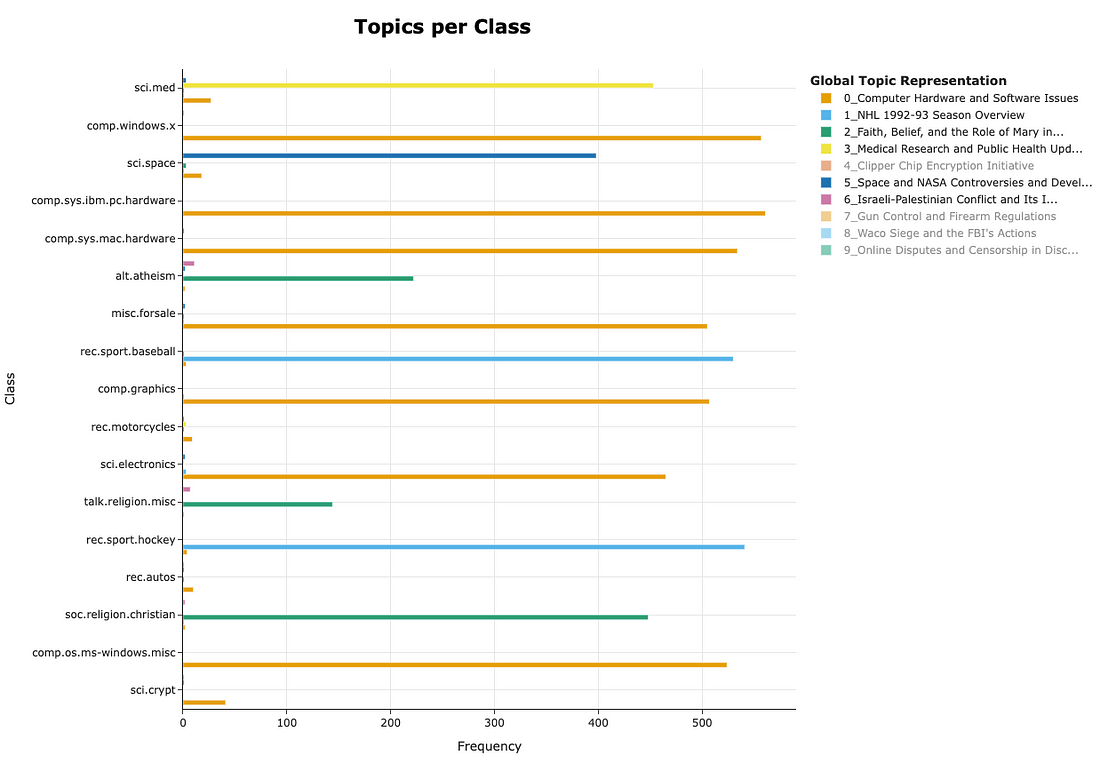
Source: Image created by the author
Zero-shot topic modeling
This variation first matches the documents with the predefined topics. Documents that didn’t match any topic are processed using the standard modular pipeline.
Define the model:
Then train/load the model:
Let’s investigate what topics we obtained as a result:
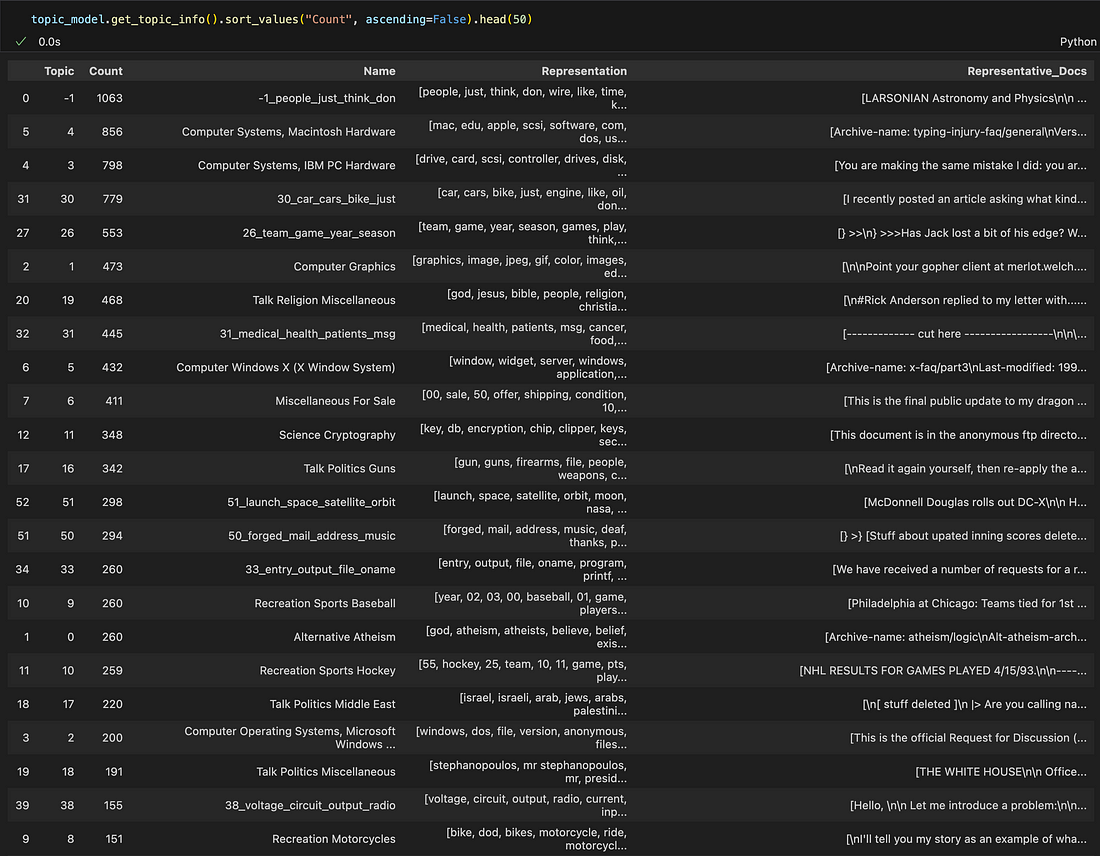
Source: Image created by the author
From the picture above we see that a significant part of the documents were matched with the predefined topics. It means that initial topics do make sense for this dataset.
Now let’s review the obtained topics’ similarities with each other.
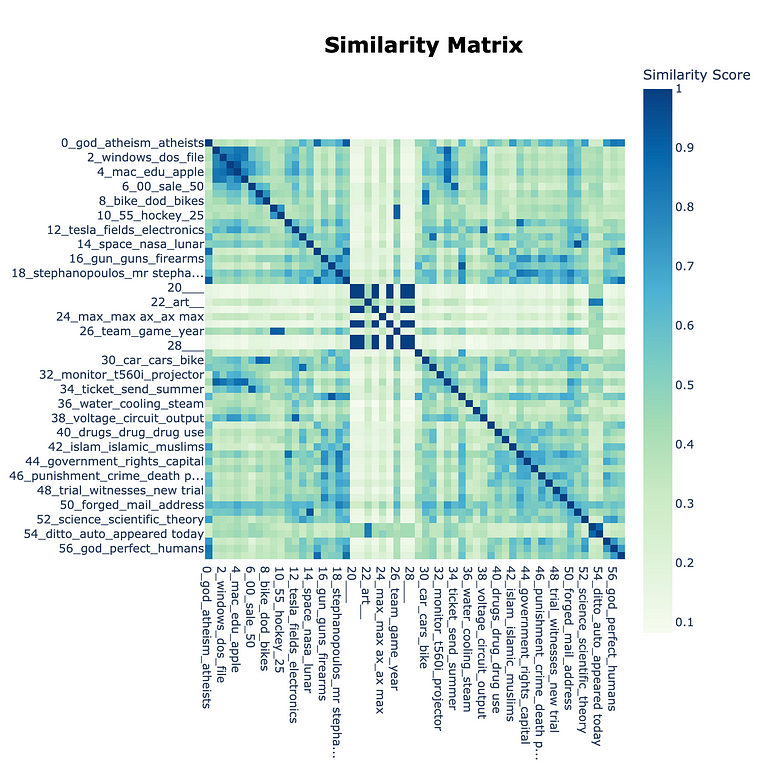
Source: Image created by the author
From the image above we can consider merging several topics into one (e.g. 30_car_cars_bike and 8_bike_dod_bikes). This is also allowed in the BERTopic framework.
Conclusion
The transition from language models to the large language models significantly changed the industry. A lot of tasks that were already resolved using some classic ML algorithms now can be solved using the correctly structured prompt and several examples. Nevertheless, we should remember that classic ML is always faster/cheaper than utilizing LLMs on a large amount of data. The more data you have — the better results you will obtain.
The BERTopic is only one of the frameworks to utilize. You can do it on your own if it’s needed. I just wanted to show how flexible it is in terms of custom module creation and combining them.
The methods described in this article outline how we can improve the already working solutions using the modern models and not how to fully substitute them using LLM pipelines. That’s something we should have in mind during the model selection for the next task we encounter. In case you can avoid the generative AI and solve your task using only the deterministic AI with approximately the same accuracy — that’s a path to follow.

Source: Image generated by the author using AI (DALL·E 3)
The full code can be found on GitHub.
Source: Medium
you might also like…

AI-Powered Smart Trash Bin – Agent of Waste Management
A new AI Smart Trash Bin Agent is set to transform waste management and recycling efforts. Powered by cutting-edge OpenAI... Read more

AI Talent Matcher: Your Hiring Assistant
Introduction Streamlining the often time-consuming and tedious process of reviewing job applications just got a whole lot smarter. Introducing the... Read more