

Introduction
Let’s solve the problem of an organization receiving multiple documents that should have the same information, but different formats, and styles and even sometimes the full scope of the document is missing. Let’s consider that multiple CVs or NDAs are arriving and we need to check if they fit in some generic template and contain all required information.
Initially, we tackle these tasks by converting documents into text using OCR.). Let it be an NDA example:

Subsequently, we remove empty spaces and add line numbers throughout the entire document.
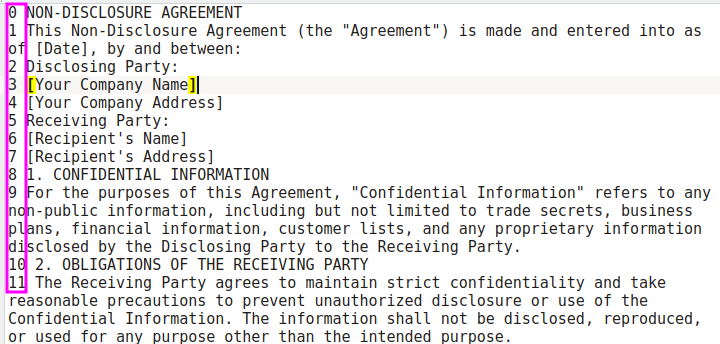
This simplifies the task for LLM, allowing it to segment the document effectively.. Now we can use prompt engineering to ask the model generate line numbers where document sections starts and propose names for the sections:


As a result, we want to receive a list of line numbers and document section names:

Of course, for larger documents, we need to break the text into chunks and process it chunk by chunk. Having enough big dataset of the same types of documents we can receive multiple versions of the same document section name. For example “Parties Identifications” can be just “Parties”. To prepare a universal document template we use text embeddings (for example with OpenAI adav2 model) to collect vector representation for each text section. After applying agglomerative clustering we will come up with a nice structure of document sections, even if they can have slightly different names:
In this picture, one can see multiple sections collected in clusters that should share the same name.
Then we can analyze the section names statistics and find what name is most often used and normalize synonyms with this correct name:
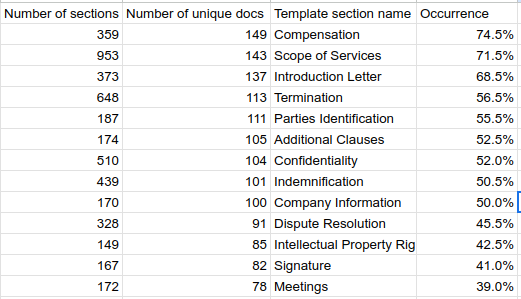
Having such a structure of a document as a list of required sections, we will use it to check with LLM each incoming document if it contains the section name.
Summary
Consequently, we automate the verification of standard documents such as declarations and CVs against a predefined template created automatically using LLM prompt engineering, embeddings, and unsupervised machine learning
you might also like…

Machine Learning Solution for Extracting Information
Oftentimes before we get to develop the Machine Learning Solution for Extracting Information, we need to test several approaches to... Read more

A digital twin of terrain – 3D model from satellite images
Hypothesis Any new project begins with an idea, undergoes development through information gathering and testing. The idea that initiated our... Read more