
Problem Statement in Related Organizations Addresses with Web-Search, spaCy, and RegExes.
Recently, one of our clients has contacted us with an interesting problem. It was an investment company, which needed to calculate potential risks for their objects of investment. They required a solution that would help generate a list of all addresses (or GPS coordinates) that were associated with specific company name, Searching for Related Organizations. The problematic our client faced was that a lot of companies could have many different subdivisions with different names in different languages. Plus, a great deal of companies have departments all over the world. Also, the company could have different hidden locations, associated with them, which are not stated directly on their legal documents. We started with a small Proof of Concept to check if there is an approach that can solve one or a few of these problems. The result had to be presented as a graph of geo-locations, with described relations to other vertices and to a given company name. It’s important to add here, that we were not provided with any data or directions. So the first problem we focused on was data sources. After a short research, we divided all available and relevant data sources into three major categories:
- Public or private registries
- Social networks
- Search engines
After giving it some thought we decided to use the last category for our PoC, since registries and social networks are hard to interact with. In addition to being hard to find, registries provide data in various formats. This makes it hard to use even a few of them for a short PoC. The approach we chose in the end did not come easy. There was one more thing we tried which didn’t work for a number of reasons. We will briefly describe what we did and how, pointing out the most valuable results and causes of failure.
The First Approach
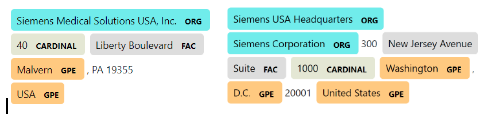
Our main idea for solving this problem was based on using spaCy. This framework has a built-in ability to tag organizations and locations in a text, the ability which we found very useful for this problem. As soon as we chose a data source, we started to analyze web-pages related to a few randomly chosen organizations. After having tagged a few web-pages texts with spaCy, we saw patterns, which appeared mostly when a company address was involved: With this pattern in mind, we started working on the following idea:
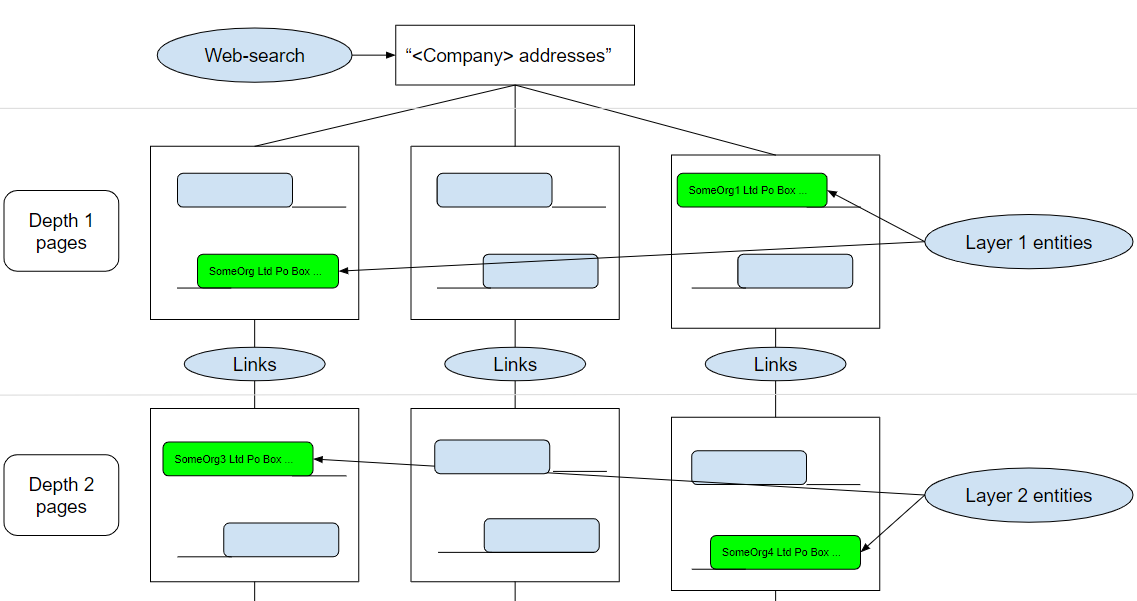
We search the web for a term that looks like “<Company> address”. The returned pages are proclaimed to be depth 1 pages. Then, we look for the above-stated pattern on each of the returned web-pages and extract a corresponding text – organization name and its address. After this, we grab all the links on those pages, proclaim their pages to be depth 2 pages and continue in a similar fashion with these pages. This process gives us a graph with vertices, corresponding to web-pages and organizations (with their addresses). The first ones are connected with each other, while the second ones are only connected to the first ones. The implementation of the process described above was a simple scrapy web-crawler. After receiving an initial list of links (depth 1 pages), the crawler looked for a pattern, collected links and proceeded to other pages, saving all results in a CSV-file. To check the pattern we used a tag-by-tag sliding window approach, which simply meant counting the number of specific tags or numerical tokens fitting into a sliding window. Despite the simplicity of this approach, it had instantly failed due to a number of reasons. First, even for a few initial links (say 100), the number of web-pages linked to them was measured in gigabytes. The process took too much time and resulted in a very small number of useful texts. Second, there were actually a lot of texts that contained neither the organization’s name, nor its address but still fit into our pattern filter. This was mostly because many words related to addresses were tagged as organizations or persons by spaCy or were not tagged at all. We decided to analyze the collected data and label them. Only ~20% of collected texts really contained both an organization name and its address. The other ~80% had a lot of extra text, missing an organization name or a meaningful part of the address. This kind of data is hard to work with. However, while analyzing this data we saw that spaCy actually works well with organization names themselves. But our pattern, in fact, was ignoring the majority of such occurrences. Another thing we found out was that almost every country has a different address template. Even despite the fact that we used corresponding spaCy models for different languages, such a simple pattern could not cover even a few address templates. This has driven us to a conclusion that such an approach is not working well for the given problem.
The Second Approach
Having taken into account all this information, we decided to simplify our PoC and focus only on US-based organizations and English pages. Plus, we decided to divide the problem into two parts: looking for related organizations and extracting the address for a single organization. To solve the first problem, we decided to try this: if some organization is mentioned on the web-pages related to a given company, then this organization is somehow connected to this company. For a moment, we would omit the question of how exactly an organization is connected to a company (opponents, subsidiaries, the same foundation group, etc.) since it appears to be a more complex problem to solve. To strengthen the observed relation, we assumed, that the company must be also mentioned on some company’s web-pages.
Extracting Potential Organization Names
We started with a simple search for related organizations using web-search and spaCy. We used Bing, however, you can use any other search engine available. We will show you the pieces of code in Python, which we used to collect data. Note that our code does not strive for elegance since it was written for a PoC and of course can be enhanced or optimized.
Extracting Potential Organization Names
We started with a simple search for related organizations using web-search and spaCy. We used Bing, however, you can use any other search engine available. We will show you the pieces of code in Python, which we used to collect data. Note that our code does not strive for elegance since it was written for a PoC and of course can be enhanced or optimized.
That is how we received 10 search results, enough for a start. Then, we passed through each search result corresponding web-page, tagged its text with spaCy (we didn’t need to tag HTML tags, scripts, attributes and so on), and extracted only those that were named ORG.
As we already mentioned, we also strengthened the power of the observed relation by checking if a given company was mentioned on the pages related to the found named entities. For this purpose, we performed a search for each found named entity.
Then, we preprocessed all collected data and saved them into csv files for further use:
Now, to check if a given company is really related to found named entities, we implemented a scrapy crawler. Using a list of URLs and a company’s name it passes through each URL and counts all mentions of a given company. Briefly, here is its main method without the whole initialization, which mostly deals with files infrastructure:
We simplified the code removing some needed try … except statements or other very specific parts of the code. Also, the decision to count the number of mentions appeared to be not completely correct: it would fail in some (not all) complex cases when the given company name consisted of two or more words. The more proper way to do this would be using the spaCy tokenizer and comparing tokens. Once the crawler had finished the work, we got a CSV file with IDs of only those potential organizations, that had a strong observed relation to a given company. A list of nearly a thousand found named entities for Samsung decreased to a list of just nearly 6 hundred. What remained looked like this:
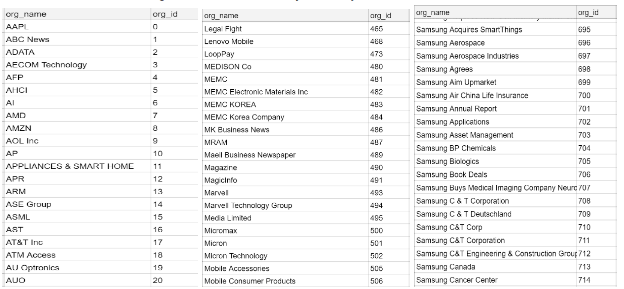
At first sight, it looked good. However, if we take a closer look at this list, we will find that a lot of named entities there are not organization names at all. For example, Samsung Annual Report is perhaps just a header of some text, but not an organization name. And there is nothing to blame spaСy for: all these named entities do look like organizations. We labeled the collected data manually. And what we saw was that this approach gives a pretty good recall. In fact, for the Samsung company, our list contained nearly 80 of their different subdivisions, legally related organizations as well as their opponents in different areas. However, it had a low precision rate: nearly 60% of those named entities were not valid organization names (nor parts of full organization names). So we needed some kind of a model for filtering out what was not a valid organization name. The approach we settled for was a little bit complex and too big to describe it here. We wrote a separate article on this topic. Work Classifying SpaCy’s ORG Named Entities with Statistical Text Analysis and Machine Learning Additionally, we tried to build a model for classifying organizations by their relationship to a given company. That model was supposed to be based on correlations between specific words and a number of mentions of a given company alongside some named entities. This approach, however, did not work.
Addresses Extraction
With the above-mentioned model, we filtered out what was not an organization name. Now that we have a list of organizations related to a given company, we need their addresses. To achieve this goal, we performed a search for each organization with a search term that looked like “<organization name> address USA”. It gave us a list of web-pages that potentially contained USA addresses of related organizations
In general, extracting addresses from an HTML page is quite tricky. The process must include finding different patterns that are common for separate countries, dealing with a list of predefined words( like country names, states, regions, etc.), and understanding what piece of a text is an address. This is harder when you need to extract an address which is written in a different language or is presented on a web-page in the form of a table with rows like Street, House #, State, etc. As for the PoC, we decided to focus on the simplest case – USA addresses written in a single p tag. For this we built a simple regex which took into account the order of spaCy’s named entities, numbers, states and, perhaps, the country. An interesting point here was that we needed to include spaCy’s organization (ORG) tag in it, since very often parts of an address where tagged with this tag. Also, we needed to build a custom regex for the US states. Even despite the fact that most of the states had a proper context around them, they were still rarely tagged by spaCy:
For the address_re here: n – is a small number, followed by up to 4 spaCy ORG, LOC, FAC or GPE tags ((l|f|g|o){0,4}), then state(s) and zip(z) and, perhaps GPE tag(g?), which would most likely by country. From this text we extract addresses in the following way:
All the code above we use in our scrapy crawler to collect addresses. Again, its main method looks like:
With this, we passed through each search result and extracted addresses of organizations. For sure, this solution is not perfect. A lot of extracted texts were not addresses at all or contained plenty of extra text. However, this happened relatively rarely compared to the amount of extracted data. All these actions resulted in a list that looks like this:
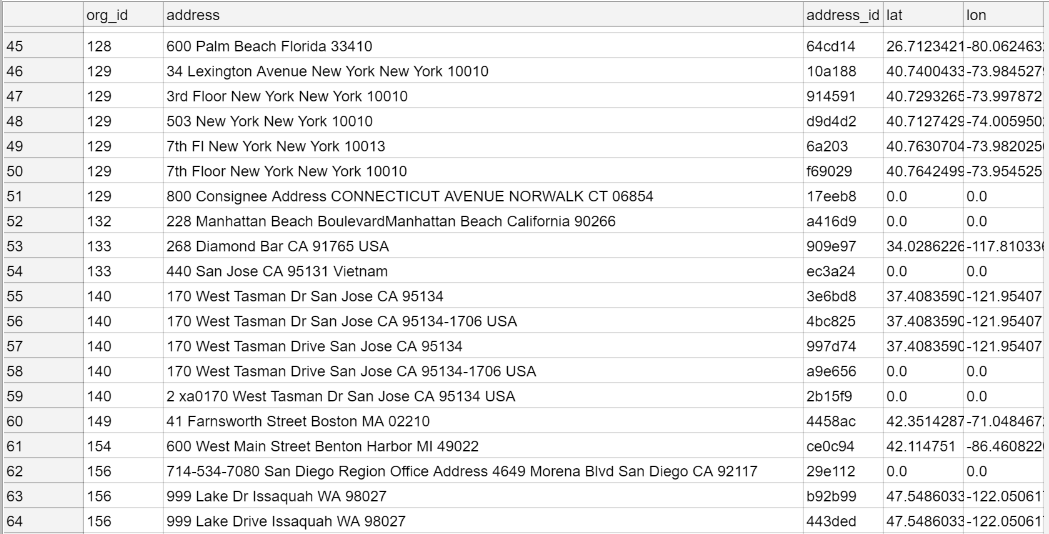
We used geopy Python package to get GPS coordinates of the address.
Note that those geocoders don’t like it when you perform multiple requests sequentially. That’s why we added a random delay. Now, having visualized all collected data, we received a map with specified locations of organizations related to some given company.
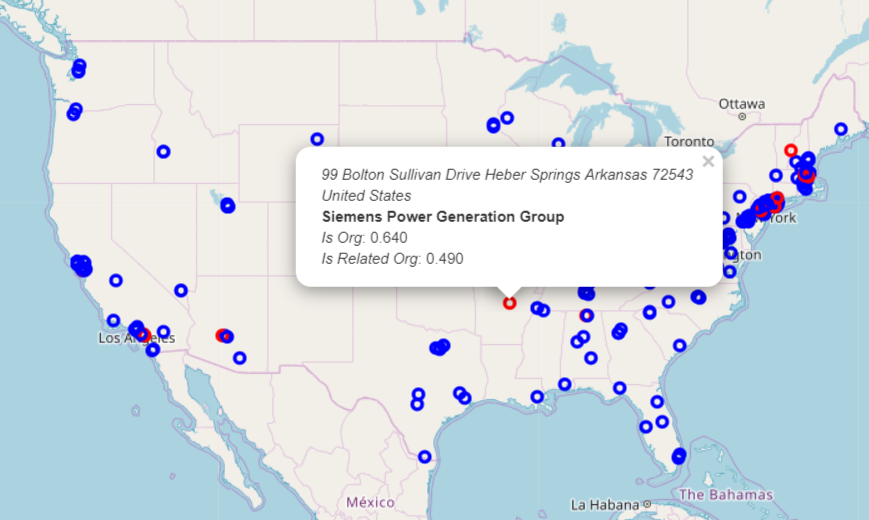
Conclusion and Further Steps
Here is a list of further steps that have the highest priority:
- Building a model to classify the type of relationship between two companies. Or, at least, between a given company and a found one. This can be achieved in various ways, starting with the analysis of word frequencies, like in the model mentioned above, and ending with complex ML systems, depending on the needed result and complexity of the problem.
- Enhancing the address extraction. This would include dictionaries of predefined words, formats for different countries and different language tagging systems.
- An analysis of organizations now related to extracted addresses, since often a few related companies are registered or located at the same address.
- Enhancing the existing approach. A lot of things were done in the simplest way possible. Many pieces of code could be improved to achieve more accuracy or more proper data.
Perhaps, some specific language systems or translators will be needed for countries like China, Japan, Korea, and others. To sum up, we now have data with which we can build a two-layer graph of entities related to a given company. The first layer of the graph would be a layer of organizations, somehow related to a given company. It, again, can include different types of subsidiaries, opponents, legally connected companies, etc. The second layer is a layer of addresses of those organizations. This graph can be used for building a general company profile, calculating investment risks, company stock price and much more Author: Volodymyr Sendetskyi, Data Scientist MindCraft Information Technology & Data Science
you might also like…
Differentiable Programming – Inverse Graphics AutoEncoder
Intro to Differentiable Programming DeepLearning classifier, LSTM, YOLO detector, Variational AutoEncoder, GAN – are these guys truly architectures in sense... Read more

Classifying SpaCy’s ORG Named Entities with Statistical Text Analysis and Machine Learning
Introduction challenge of Classifying SpaCy’s ORG Named Entities with Statistical Text Analysis Recently, we were tagging a lot of texts... Read more