

Image Classification, Object Detection, and Semantic segmentation
Introduction
Imagine we have a project, where we need to get the precise mask of the object, where an object may be from a variety of different classes. When I mention a “variety” of different classes, it means that it’s not 10, 100, or 1000 unique classes, the object may be absolutely anything.
The idea behind this project is to get the mask of the main object on the image. The so-called “main” object may be a cat, van, microwave, airplane, etc. Also, we pretend that the image has a text description, which may be from a single word to a several-sentence description, outlining the scene.

From the text description, we may obtain the list of the most valuable objects using LLMs (not the topic of this article). In this article, we will focus on the general solution to the described task, which, if needed, may be adapted for the more specific use cases.
The idea behind the scene
The defined task may be solved using 2 different approaches. The first one involves training the classic CV models using supervised learning on the selected dataset. The second one utilizes the power of the modern zero-shot models without additional fine-tuning on the selected dataset (fine-tuning still may be the case for such models, but it is not a topic of this article). In the picture below you may understand the overall pipeline for the 2 different approaches. There also may be many mixed solutions when we combine classic and zero-shot approaches.
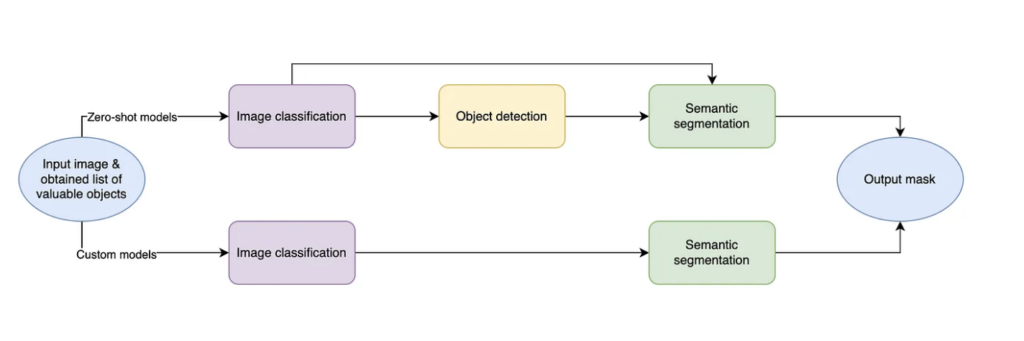
With the current understanding of the task let’s dive into the current world of the SOTA models for Image classification, Object detection, and Semantic segmentation.
I have gathered the following information about each of the models:
- number of parameters (one of the most important parameters, decided to focus on the more lightweight models)
- out-of-the-box number of known classes (“Any” for zero-shot models)
- links to the relevant docs, GitHub, HuggingFace (any relevant information source)
- license (type)
- notes (the diverse column with personal observations and limitations about the model)
Every model was assessed with a score, which shows the level of suitability for easy, efficient, and powerful implementation from 1 to 5. Model evaluation was based on the following criteria:
- model metrics on the PapersWithCode
- detailed documentation and a broad community (no one wants to work with a model that has no information because it will take a lot of extra time to understand and guess a lot of things by yourself)
- license (ability to use the model for the commercial use)
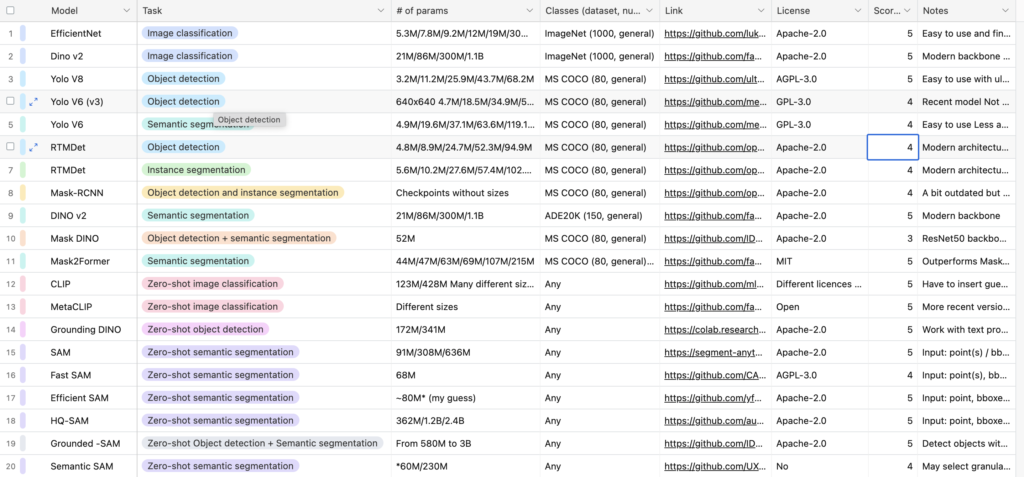
Based on the described criteria, I have selected prizewinners in each category. I have selected EfficientNet in Image classification, Yolo V8 in Object detection, Dino v2 and Mask2Former in Semantic segmentation, CLIP and MetaCLIP in Zero-shot Image classification, GroundingDINO in Zero-shot Object detection, and SAM and HQ-SAM in Zero-shot semantic segmentation. In case you have a different opinion, let everyone know about the other possible choices in the comments section.
For our task, I recommend using the zero-shot approach because of its flexibility. I have utilized the CLIP -> GroundingDINO -> SAM approach to improve the SAM performance by providing the GroundingDINO bounding boxes.
Pipeline
Let’s take the image from the COCO dataset and create a custom description: “The man skiing on his new snowboard!”.

Imagine we have obtained a list of [“man”, “snowboard”] as valuable objects on the image (note, skiing is not the object itself). Now let’s incorporate the power of the CLIP model.
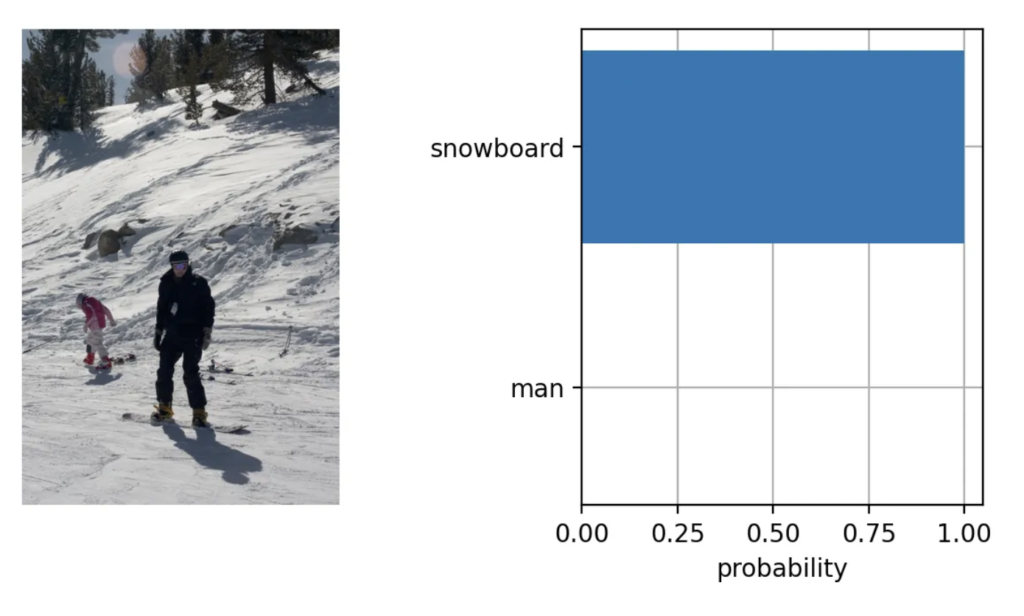
So here we go, our main object is the snowboard. Now let’s obtain its bounding box using the GroundingDINO model.

In doing so, the snowboard was correctly detected using a zero-shot model, even when the snowboard was partly under the snow.
And finally, let’s take a look at how SAM can deal with this snowboard bounding box input.

So, the snowboard was segmented with pretty high accuracy despite the obstacles.
Code
Conclusion
In situations when you may have a whole bunch of possible classes, or don’t have enough data to train your custom model — you should utilize the zero-shot models. Zero-shot models are our future, and the future is coming with a backpack of interesting and powerful models.
you might also like…

What in the Clouds – Thermal Object Tracking
Introduction How easy could it be to find something? When you look for clothes in a closet, all the objects... Read more

Realtime presentation transcription and clear meeting summary using GPT4
Introduction Almost no one can imagine our life without presentations and demos via videoconferences. With this in mind, think about... Read more