

Unlocking the Power of GPT-Generated Private Corpora
Introduction
Nowadays the world has a lot of good foundation models to start your custom application with (gpt-4o, Sonnet, Gemini, Llama3.2, Gemma, Ministral, etc.). These models know everything about history, geography, and Wikipedia articles but still have weaknesses. Mostly there are two of them: level of details (e.g., the model knows about BMW, what it does, model names, and some more general info; but the model fails in case you ask about number of sales for Europe or details of the specific engine part) and the recent knowledge (e.g., Llama3.2 model or Ministral release; foundation models are trained at a certain point in time and have some knowledge cutoff date, after which the model doesn’t know anything).
This article is focused on both issues, describing the situation of imaginary companies that were founded before the knowledge cutoff, while some information was changed recently.
To address both issues we will use the RAG technique and the LlamaIndex framework. The idea behind the Retrieval Augmented Generation is to supply the model with the most relevant information during the answer generation. This way we can have a DB with custom data, which the model will be able to utilize. To further assess the system performance we will incorporate the TruLens library and the RAG Triad metrics.
Mentioning the knowledge cutoff, this issue is addressed via google-search tools. Nevertheless, we can’t completely substitute the knowledge cutoff with the search tool. To understand this, imagine 2 ML specialists: first knows everything about the current GenAI state, and the second switched from the GenAI to the classic computer vision 6 month ago. If you ask them both the same question about how to use the recent GenAI models, it will take significantly different amount of search requests. The first one will know all about this, but maybe will double-check some specific commands. And the second will have to read a whole bunch of detailed articles to understand what’s going on first, what this model is doing, what is under the hood, and only after that he will be able to answer.
Basically it is like comparison of the field-expert and some general specialists, when one can answer quickly, and the second should go googling because he doesn’t know all the details the first does.
The main point here is that a lot of googling provides comparable answer within a significantly longer timeframe. For in chat-like applications users won’t wait minutes for the model to google smth. In addition, not all the information is open and can be googled.
Data
Right now it may be hard to find a dataset, that is not previously used in the training data of the foundation model. Almost all the data is indexed and used during the large models’ pretraining stage.

Source: Image generated by the author using AI (Bing)
That’s why I decided to generate the one myself. For this purpose, I used the chatgpt-4o-latest via the OpenAI UI and several continuous prompts (all of them are similar to the ones below):
As a result, I generated a private corpus for 4 different companies. Below are the calculations of the tokens to better embrace the dataset size.
Below you can read the beginning of the Ukraine Boats Inc. description:
The complete private corpus can be found on GitHub.
For the purpose of the evaluation dataset, I have also asked the model to generate 10 questions (about Ukraine Boats Inc. only) based on the given corpus.
Here is the dataset obtained:
Now, when we have the private corpus and the dataset of Q&A pairs, we can insert our data into some suitable storage.
Data propagation
We can utilize a variety of databases for the RAG use case, but for this project and the possible handling of future relations, I integrated the Neo4j DB into our solution. Moreover, Neo4j provides a free instance after registration.
Now, let’s start preparing nodes. First, we instantiate an embedding model. We used the 256 vector dimensions because some recent tests showed that bigger vector dimensions led to scores with less variance (and that’s not what we need). As an embedding model, we used the text-embedding-3-small model.
After that, we read the corpus:
Furthermore, we utilize the SentenceSplitter to convert documents into separate nodes. These nodes will be stored in the Neo4j database.
Hybrid search is turned off for now. This is done deliberately to outline the performance of the vector-search algorithm.
We are all set, and now we are ready to go to the querying pipeline.
Source: Image created by the author
Pipeline
The RAG technique may be implemented as a standalone solution or as a part of an agent. The agent is supposed to handle all the chat history, tools handling, reasoning, and output generation. Below we will have a walkthrough on how to implement the query engines (standalone RAG) and the agent approach (the agent will be able to call the RAG as one of its tools).
Often when we talk about the chat models, the majority will pick the OpenAI models without considering the alternatives. We will outline the usage of RAG on OpenAI models and the Meta Llama 3.2 models. Let’s benchmark which one performs better.
All the configuration parameters are moved to the pyproject.toml file.
The common step for both models is connecting to the existing vector index inside the neo4j.
OpenAI
Firstly we should initialize the OpenAI models needed. We will use the gpt-4o-mini as a language model and the same embedding model. We specify the LLM and embedding model for the Settings object. This way we don’t have to pass these models further. The LlamaIndex will try to parse the LLM from the Settings if it’s needed.
QueryEngine
After that, we can create a default query engine from the existing vector index:
Furthermore, we can obtain the RAG logic using simply a query() method. In addition, we printed the list of the source nodes, retrieved from the DB, and the final LLM response.
Here is the sample output:
As you can see, we created custom node ids, so that we can understand the file from which it was taken and the ordinal id of the chunk. We can be much more specific with the query engine attitude using the low-level LlamaIndex API:
Here we specified custom retriever, similarity postprocessor, and refinement stage actions.
For further customization, you can create custom wrappers around any of the LlamaIndex components to make them more specific and aligned with your needs.
Agent
To implement a RAG-based agent inside the LlamaIndex, we need to use one of the predefined AgentWorkers. We will stick to the OpenAIAgentWorker, which uses OpenAI’s LLM as its brain. Moreover, we wrapped our query engine from the previous part into the QueryEngineTool, which the agent may pick based on the tool’s description.
To further use the agent, we need an AgentRunner. The runner is more like an orchestrator, handling top-level interactions and state, while the worker performs concrete actions, like tool and LLM usage.
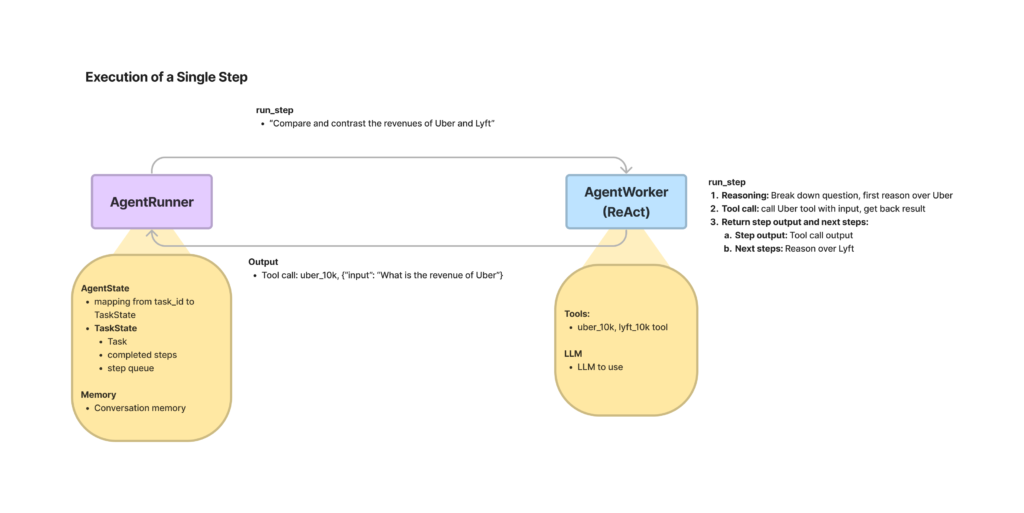
Source: Image taken from the LlamaIndex docs
To test the user-agent interactions efficiently, I implemented a simple chat-like interface:
Here is a sample of the chat:
What we can see, is that for the correct vector search you need to specify the input questions with more details, that can be semantically matched.
Open source
As an open source model, we have utilized the meta-llama/Llama-3.2–3B-Instruct. This choice was based on the model latency & performance trade-off. First things first we need to authenticate our HuggingFace account via an access token.
To use the Llama as an LLM inside the LlamaIndex, we need to create a model wrapper. We will use a single NVIDIA GeForce RTX 3090 to serve our Llama 3.2 model.
QueryEngine
The interfaces are the same. Example output is below:
Agent
For the OpenAI models, LlamaIndex has a special agent wrapper designed, but for the open-source models we should use another wrapper. We selected ReActAgent, which iteratively does reasoning and acting until the final response is ready.
Below is the same discussion but with a different Agent under the hood:
As we can see, the agents reason differently. Given the same questions, the two models decided to query the tool differently. The second agent failed with the tool once, but it’s more an issue of the tool description than the agent itself. Both of them provided the user with valuable answers, which is the final goal of the RAG approach.
In addition, there are a lof of different agent wrappers that you can apply on top of your LLM. They may significantly change a way the model interacts with the world.
Evaluation
To evaluate the RAG, nowadays there are a lot of frameworks available. One of them is the TruLens. Overall RAG performance is assessed using the so-called RAG Triad (answer relevance, context relevance, and groundedness).
To estimate relevances and groundedness we are going to utilize the LLMs. The LLMs will act as judges, which will score the answers based on the information given.
TruLens itself is a convenient tool to measure system performance on a metric level and analyze the specific record’s assessments. Here is the leaderboard UI view:
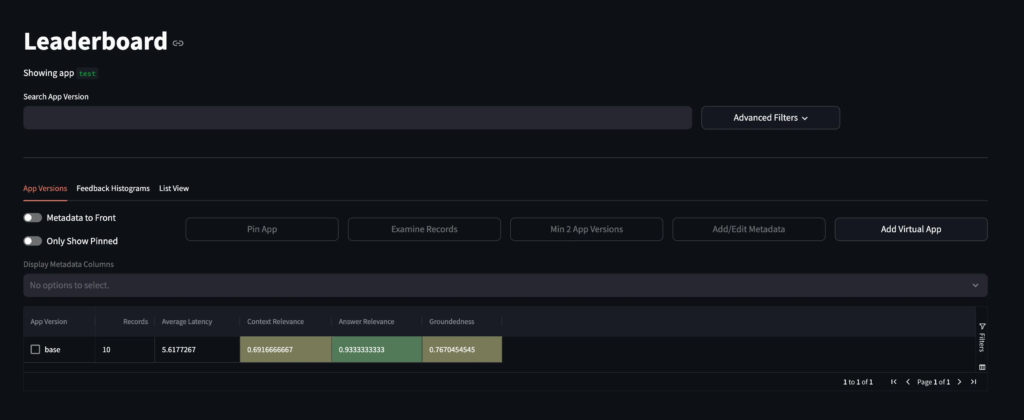
Source: Image created by the author
Below is the per-record table of assessments, where you can review all the internal processes being invoked.
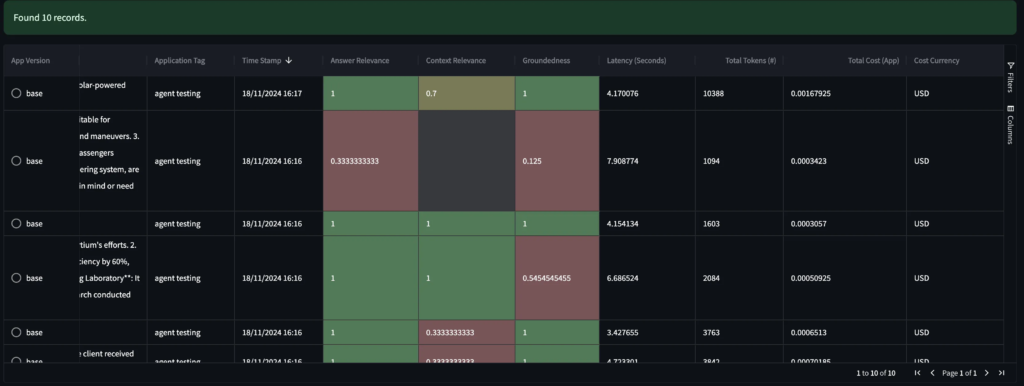
Source: Image created by the author
To get even more details, you can review the execution process for a specific record.
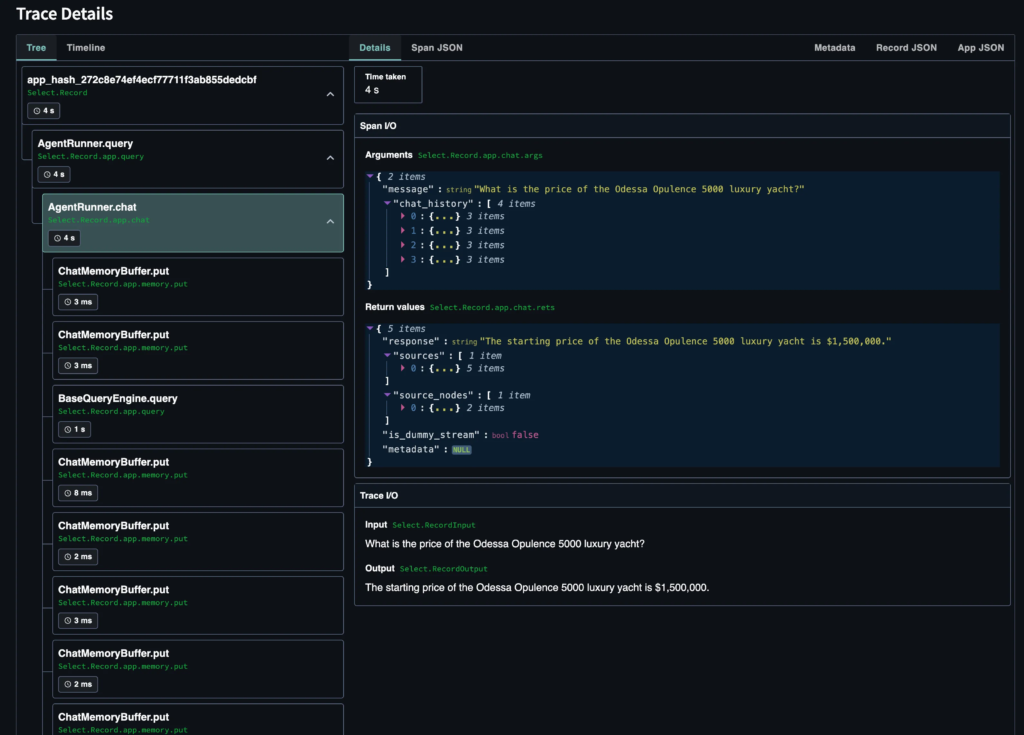
Source: Image created by the author
To implement the RAG Triad evaluation, first of all, we have to define the experiment name and the model provider. We will utilize the gpt-4o-mini model for the evaluation.
After that, we define the Triad itself (answer relevance, context relevance, groundedness). For each metric, we should specify inputs and outputs.
Furthermore, we instantiate the TruLlama object that will handle the feedback calculation during the agent calls.
Now we are ready to execute the evaluation pipeline on our dataset.
We have conducted experiments using the 2 models, default/custom query engines, and extra tool input parameters description (ReAct agent struggled without the explicit tool input params description, trying to call non-existing tools to refactor the input). We can review the results as a DataFrame using a get_leaderboard() method.
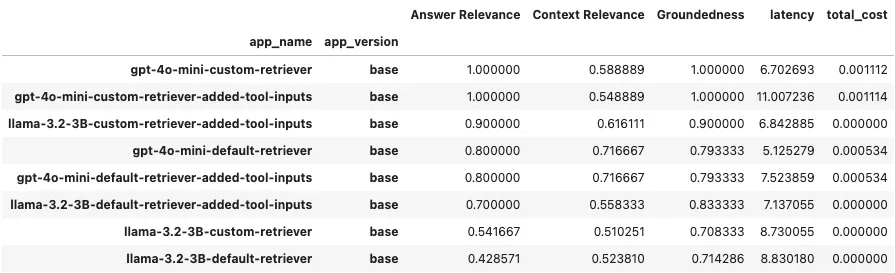
Source: Image created by the author
Conclusion
Source: Image generate by the author using AI (Bing)
We obtained a private corpus, incorporating GPT models for the custom dataset generation. The actual corpus content is pretty interesting and diverse. That’s the reason why a lot of models are successfully fine-tuned using the GPT-generated samples right now.
Neo4j DB provides convenient interfaces for a lot of frameworks while having one of the best UI capabilities (Aura). In real projects, we often have relations between the data, and GraphDB is a perfect choice for such use cases.
On top of the private corpus, we implemented different RAG approaches (standalone and as a part of the agent). Based on the RAG Triad metrics, we observed that an OpenAI-based agent works perfectly, while a well-prompted ReAct agent performs relatively the same. A big difference was in the usage of a custom query engine. That’s reasonable because we configured some specific procedures and thresholds that align with our data. In addition, both solutions have high groundedness, which is very important for RAG applications.
Another interesting takeaway is that the Agent call latency of the Llama3.2 3B and gpt-4o-mini API was pretty much the same (of course the most time took the DB call, but the difference is still not that big).
Though our system works pretty well, there are a lot of improvements to be done, such as keyword search, rerankers, neighbor chunking selection, and the ground truth labels comparison. These topics will be discussed in the next articles on the RAG applications.
Private corpus, alongside the code and prompts, can be found on GitHub.
Title photo by Jaredd Craig on Unsplash
you might also like…

LLM-Powered Metadata Extraction Algorithm
Described on an Amazon Consumer Feedback dataset Introduction Did you know that businesses receive thousands of customer reviews daily, each... Read more

Your AI-Powered Guardian: Policy Compliance Check Agent
Introducing our AI Agent – Policy Compliance Check Agent. This cutting-edge solution empowers you to effortlessly ensure adherence to critical... Read more