
Subject: Automated Document Classification with Machine Learning, Data extraction, Document Classification
Data Science areas: Natural Language Processing, Computer vision, Optical Character Recognition
Architectures: Logistic Regression, Random Forests
Tools: Python, Tensorflow, Sklearn, Tesseract
Summary: MindCraft developed a ground-breaking Machine Learning software solution for automated document classification and data extraction. This model can automatically capture, recognize, process and classify printed, handwritten and mixed documents. Created for the banking industry, the system can apply to any domain with a vast document flow and a need for smart data processing and management.
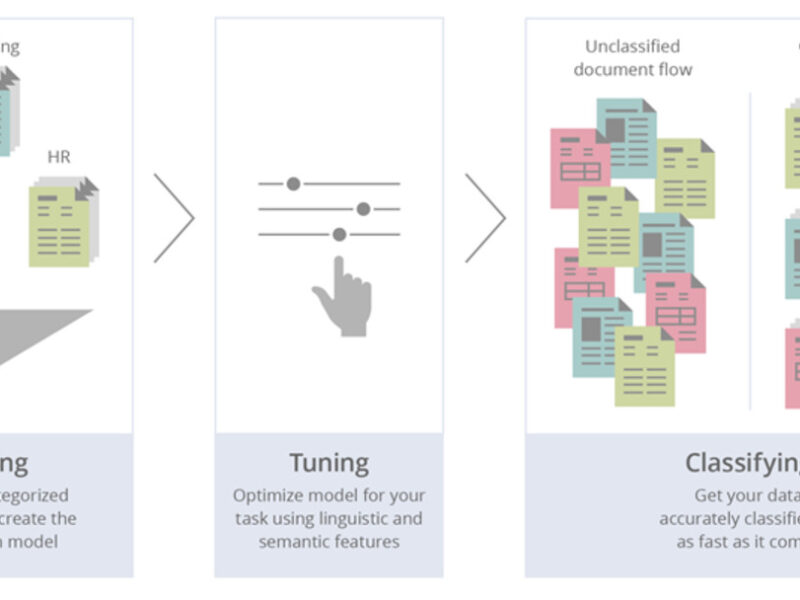
Our Main Challenges in Document Classification
A retail bank addressed MindCraft asking for help with document classification. Their organization has an input queue of documents, scanned or captured with a camera or cell phone. Before the information can be processed, OCRed and stored, the documents need to be classified by type. Reason is that different types of text content can be processed in different ways. Some can be easily captured by fields and OCRed. Others, like handwriting, need manual tagging and then storing. Types of documents can vary (as shown below):
- a regular printed letter
- a handwritten document containing a table
- a mixed-type document

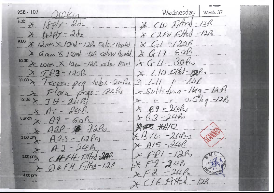

As you can see, the quality of these incoming documents is far from perfect. Processing such inaccurate data threatened with many possible difficulties. Still, we decided to try and handle this problem. The conditions didn’t even resemble the classical options. The other world-class document classification platforms couldn’t work with similar papers at all.

Building a Machine Learning Solution
MindCraft created a machine learning-based software solution which allows the processing and classification of these and similar documents. To train our system, we took around 10K of real documents of 22 different types and started building models.
The first model we created was based on Natural Language Processing. We started with recognizing the actual texts contained in these documents. Then, we prepared a dictionary of the most relevant words. It enabled us to create a model taking this text as a basis. Result of doing so reached 70% of quality recognition out of the set of test documents.
As it often happens, the best results appear while using mixed approaches. So, we added information about how the document looks like by means of a few computer vision techniques. This model resulted in around 70% of accurate classification from 22 types of documents (basically the same ones as before). Finally, we put these two approaches together. After a couple of hours of training received 99% of accuracy on the training data and around 90% on the test datasets.
Accuracy train: 0.990167 test: 0.891444
Accuracy train: 0.990167 test: 0.891444
Accuracy train: 0.990167 test: 0.890909
Accuracy train: 0.990167 test: 0.891444
Accuracy train: 0.990167 test: 0.891444
Accuracy train: 0.990167 test: 0.891979
Accuracy train: 0.990167 test: 0.891979
Accuracy train: 0.990167 test: 0.892513
Results of Automated Document Classifier
Currently, our model is ready to be put into production and used for document classification. It allows classifying dozens of different document categories. Retraining the model will help to new categories overtime if needed. A system like this could automate various document processing tasks which are now performed manually. This will lead to a significant boost in efficiency, especially for large enterprises. If you look beyond just the documents classification, this system can be applied to anything visual which contains text – like product recognition by the label, etc
The second part of the project was AI Document Recognition Software for FinTech
Regards
Team MindCraft
you might also like…
Ecommerce Price Prediction System
Subject: Price Prediction System, Prediction Accuracy Evaluation, Deep LearningData Science areas: Feature Analysis, Estimators, Machine LearningArchitectures: Linear Regression, Boosting Regressors,... Read more
AI Document Recognition Software for FinTech
Subject: Automated Document Classification, Document Capturing, Data Extraction, AI Document RecognitionBusiness Areas: Banking, FinTech, RetailData Science Areas: Computer Vision, Machine... Read more