
Case Study: Building an End-to-End NLP Engine for GDPR-Sensitive Document Processing
Executive Summary
- Project Goal: Development of a high-precision, GDPR-compliant NLP engine for automated sensitive-data identification within complex, unstructured document sets.
- Core Disciplines: Advanced NLP, Named Entity Recognition (NER), Optical Character Recognition (OCR), and document classification.
- Architecture Strategy: A hybrid, modular pipeline fusing classical machine learning (SVC, n-gram classifiers) with deep learning (Transformer embeddings, CNNs) and deterministic heuristic validation.
- Technical Stack: Python, Pandas, NumPy, TensorFlow, Keras, Tesseract OCR, AzureOCR, spaCy, SciPy, NLTK, OpenCV.
- Deployment Infrastructure: Fully isolated, air-gapped Azure environment ensuring absolute data sovereignty and zero reliance on external third-party services.
- Key Performance Indicators: 90%+ NER accuracy; 92%+ weighted-average F1 score.
The Challenge
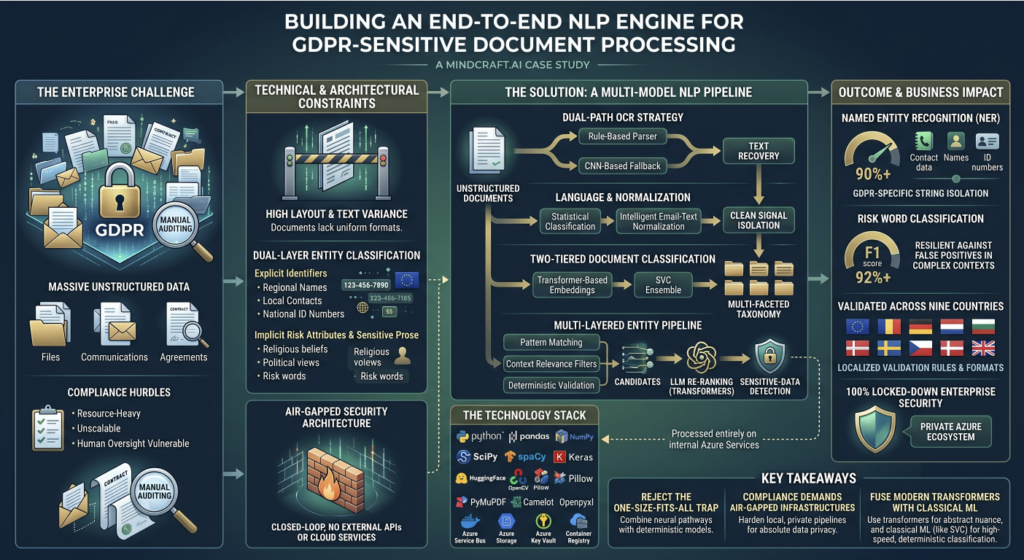
The Enterprise Regulatory Landscape
Modern organizations process massive volumes of unstructured data—including corporate files, internal communications, and legal agreements. Managing these documents while strictly adhering to regional data regulations like GDPR presents a major logistical hurdle. Manually auditing unstructured documents for compliance is resource-heavy, unscalable, and highly vulnerable to human oversight. To modernize this process, the objective was to design, train, and deploy a production-grade, multi-national Natural Language Processing (NLP) pipeline capable of automating sensitive entity detection at scale.
Core Technical & Architectural Constraints
Building a reliable system for compliance auditing required overcoming several complex engineering and security challenges:
- High Layout and Text Variance: Unstructured documents lack uniform formats or standardized structural templates. The system needed the intelligence to parse through unpredictable text architectures without relying on rigid, rule-based layouts.
- Dual-Layer Entity Classification: The system could not rely on standard Named Entity Recognition (NER) alone. It had to be engineered to accurately isolate two distinct classes of data across nine different countries:
- Explicit Identifiers: Highly structured data points such as diverse regional names, local contact details, and various national identification number formats.
- Implicit Risk Attributes & Sensitive Prose: Deep contextual data points buried within dense text, including sensitive personal attributes like religious beliefs, political views, and specific risk words.
- Air-Gapped, Closed-Loop Security Architecture: Because the pipeline directly handles highly sensitive personal information subject to strict legal frameworks, data privacy was absolute. The technical architecture required a deployment strategy that prohibited external data exposure, ensuring absolutely no data was transmitted to external APIs or third-party cloud services.
Ultimately, the challenge lay in delivering an advanced machine learning framework that could hit production-level accuracy milestones while operating within a completely locked-down, localized environment.
The Technical Approach
Instead of relying on a “one-size-fits-all” model, MindCraft.ai designed a sophisticated, multi-model architecture. A team of 2–5 dedicated AI experts handled the full machine learning pipeline—from dataset collection and annotation to feature engineering, model training, and production deployment.
Multi-Model Pipeline Breakdown
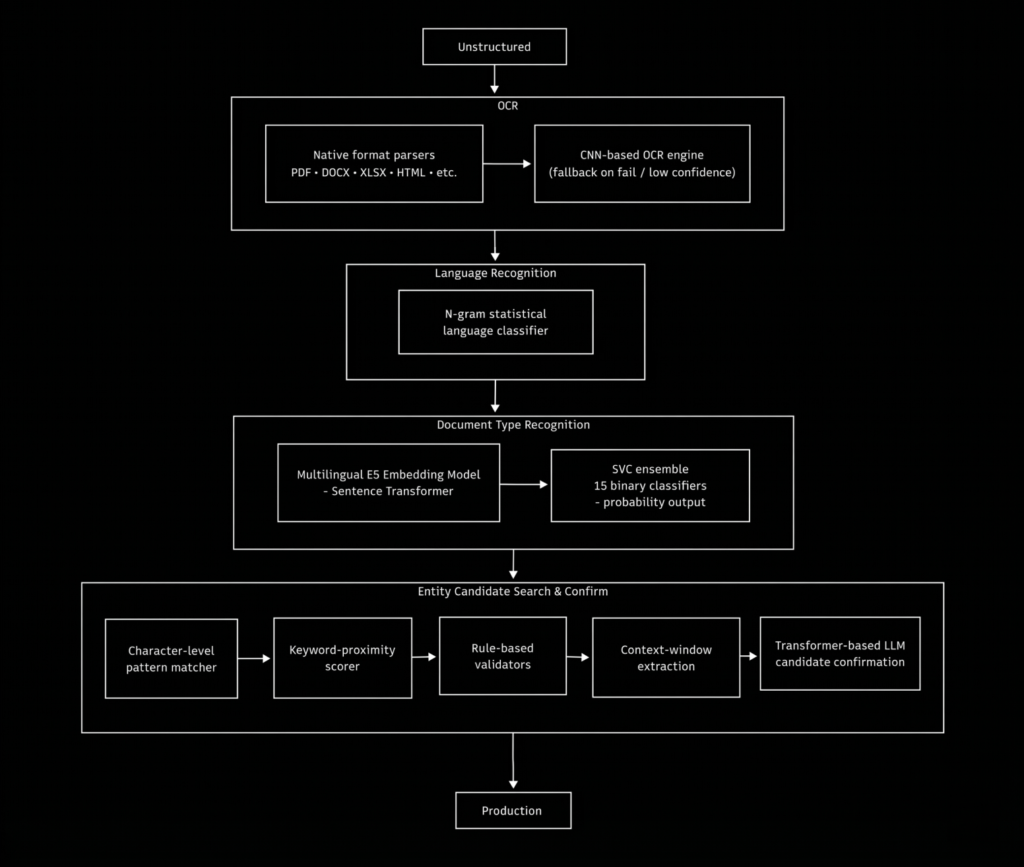
The Architecture Breakdown
To manage heterogeneous formats and sensitive-data patterns, the system employed a staged pipeline that fused classical and neural methodologies for robust classification and extraction:
- Dual-Path OCR Strategy: Integrated rule-based parsers for structured format extraction with a CNN-based fallback, ensuring high-fidelity text recovery regardless of document quality or density.
- Statistical Language & Normalization: Applied n-gram language classification alongside intelligent email-text normalization, isolating high-value signals from unstructured header and signature noise.
- Two-Tiered Document Classification: Utilized transformer-based embeddings and an SVC ensemble to map documents against a multi-faceted taxonomy, employing probabilistic scoring to mitigate inter-class ambiguity and ensure governance.
- Multi-Layered Entity Pipeline: Combined character-level pattern matching, contextual relevance filters, and deterministic structural validation to identify candidates, while deploying transformer-based LLM re-ranking to resolve ambiguous sensitive-data contexts.
The Technology Stack
- Core Engineering & Math: Python, Pandas, NumPy, SciPy, NLTK, spaCy.
- Deep Learning Frameworks: TensorFlow, Keras, sentence-transformers, huggingface-hub, tokenizers.
- Text Extraction & Ingestion: Tesseract OCR, OpenCV, Pillow, AzureOCR, PyMuPDF, Camelot, openpyxl, beautifulsoup4, etc.
- Orchestration & Deployment: Managed via Azure Service Bus workers and Docker/Kubernetes pipelines, deployed within secure Azure infrastructure (Blob Storage, Key Vault, Container Registry) with zero reliance on external third-party data services.
The Business Value
The hybrid AI approach effectively solved the client’s compliance overhead, establishing a scalable, airtight production environment:
- Named Entity Recognition (NER): Achieved over 90% accuracy in isolating complex, multi-national GDPR-specific strings, including contact data, names, and regional identity numbers.
- Risk Word Classification: Document auditing scored a 92%+ weighted-average F1 score, proving highly resilient against false positives in intricate contextual layouts.
- Validated Across Nine Countries: Successfully automated localized validation rules, handling diverse regional formatting standards flawlessly.
- 100% Locked-Down Enterprise Security: The entire engine was seamlessly operationalized within the private Azure ecosystem, maintaining strict corporate data privacy and processing limits.
Key Takeaways
- Reject the One-Size-Fits-All Trap: Complex enterprise workflows rarely benefit from a single LLM or classical model. The ideal architecture isolates discrete problems (e.g., leveraging specialized neural pathways for semantic understanding while utilizing deterministic models for structured data) and fuses them into a unified, high-precision pipeline.
- Compliance Demands Air-Gapped Infrastructures: When operating under strict regulatory frameworks, external API reliance is a liability. Engineering local, private pipelines within a hardened Azure infrastructure guarantees absolute data privacy and total control over the information lifecycle
- Fuse Modern Transformers with Classical ML: While transformer-based embeddings excel at capturing abstract semantic nuance, classical machine learning approaches (such as SVC ensembles) remain superior for deterministic, high-speed classification. Fusing these methodologies ensures systems remain both computationally efficient and highly auditable.
Overall Rating: ⭐⭐⭐⭐⭐ (5.0 / 5.0)
you might also like…

Ensuring Reliability and Security in Multi-Agent AI Architectures
Introduction As the AI landscape shifts from single-purpose chatbots to complex Multi-Agent Systems (MAS), the potential for automation has reached... Read more
The Rise of the AI FDE—And Why Independence Matters
A massive shift is underway in how software is delivered. The era of “sign the contract and figure it out... Read more