

Described on an Amazon Consumer Feedback dataset
Introduction
Did you know that businesses receive thousands of customer reviews daily, each containing valuable insights? Yet, making sense of this data and processing it is a challenging task. The volume of unstructured data is constantly growing — social media posts, customer reviews, articles, etc. Processing this data and extracting meaningful insights is crucial for businesses to understand customer feedback.
Many techniques were created to process this unstructured data, such as sentiment analysis, keyword extraction, named entity recognition, parsing, etc. But often, these methods fail on more complex tasks. The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with.
Use Case
Suppose you own a business and want to understand how customers feel about your products and identify possible ways to improve them. While numerical ratings in reviews provide a general understanding of the satisfaction with the product, they could be more meaningful in terms of specific features. To truly understand the feedback on the product, you have to process a large number of reviews: understand the pros and cons, what could be improved, the average usage time of the product, etc. A human-level understanding of the text is required to extract these essential features for further analysis. This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze.
This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API.
Data
We decided to use the Amazon reviews dataset. Below is a citation from the readme of the chosen dataset:
The Amazon reviews dataset consists of reviews from Amazon. The data span a period of 18 years, including ~35 million reviews up to March 2013. Reviews include product and user information, ratings, and a plaintext review. It is used as a text classification benchmark in the following paper: Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
The Amazon reviews full score dataset is constructed by randomly taking 600,000 training samples and 130,000 testing samples for each review score from 1 to 5. In total there are 3,000,000 training samples and 650,000 testing samples.
The files train.csv and test.csv contain all the training samples as comma-sparated values. There are 3 columns in them, corresponding to class index (1 to 5), review title and review text.
Data processing
Since our main area of interest is extracting metadata from reviews, we had to choose a subset of reviews and label it manually with selected fields of interest. We have chosen the following structure to be extracted from reviews:
Here is the breakdown of the fields:
- Pros: list of events or features that had a positive impact on the customer experience
- Cons: list of events or features that hurt the customer experience
- Product features: list of features mentioned in the review
- Use case: the use case of the product mentioned in the review
- Experience: the customer’s overall experience based on the review’s semantics. It can be positive, negative, or mixed
- Usage duration: how long the customer used the product when writing the review if mentioned.
- Improvements: list of features or fixes that the customer mentioned in the review
- Stars of review: LLM’s prediction of the review star, based on the review text
We chose 62 reviews as a test dataset and subsequently labeled their metadata.
Some of the valuable fields (support quality and whether the customer requested a refund), weren’t present in our subset, but we left them in our pipeline. Just in case they are present in your dataset.
Pipeline

Source: Image generated by the author using AI (Flux AI)
We leveraged the zero-shot prompting approach using OpenAI’s LLM, specifically GPT-4o. It allows for the interpretation of reviews and data extraction without needing large amounts of labeled datasets. It reduces training and pipeline setup time while enabling fast setup and results calculation. The zero-shot technique helps to perform tasks that LLM wasn’t explicitly trained for, based on prompts with a current task description.
An effective prompt that explains to LLM how to process the data and what we expect as a result is the key to success. Here is the prompt that we utilized for our task:
One of the significant challenges is processing the output of the LLM. The model’s response might not always be what you expect, as it might hallucinate, truncate the output, etc. We utilized the new OpenAI feature — structured output to address this issue. It ensures 100% consistency with the JSON schema you provide. Structured output allows input as a JSON schema:
Or, similarly a pydantic model:
In our implementation, we used the LangChain framework, which facilitates work with different LLMs and allows easy switching between various models. To reduce costs, we used batch API that offers a 50% discount on requests to OpenAI API.
Metrics
We computed metrics in two key areas to assess the model’s accuracy: stars rating prediction and metadata extraction. For star ratings, we compared the model’s predictions against the ground truth ratings available in the initial dataset. As for metadata extraction, we designed a custom embedding-based metric to compare predictions with the labels.
Stars accuracy
For stars, we simply chose 100 reviews (a bit more than our labeled dataset). To evaluate the accuracy of our model’s star rating predictions, we employed the Root Mean Squared Error (RMSE) metric. RMSE measures the error between predicted and actual errors with a heavy impact of significant errors on the metric, as it squares the difference between values.
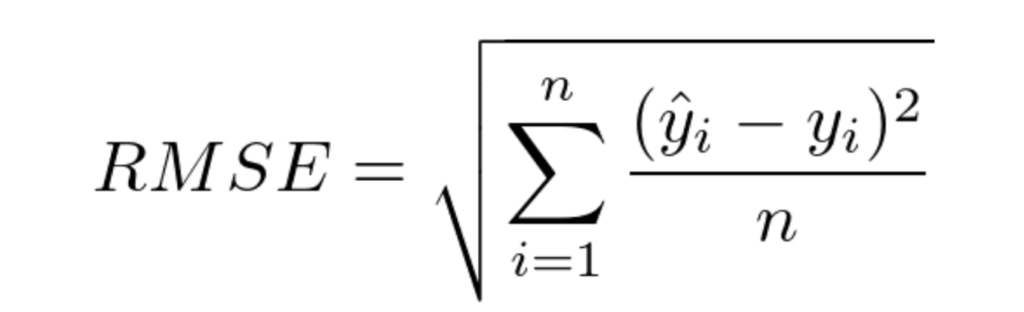
Source: Image taken from source
RMSE computed on predictions of the LLM using the zero-shot technique without prior model fine-tuning resulted in 0.76. You may think it’s not that close to 0, but for reviews having a +- 1 star is okay due to personal biases in estimations.
We visualized the confusion metric for the obtained results to understand the nature of the errors. It shows the frequency of predictions on different star ratings assigned and how they correlate to stars in labels.
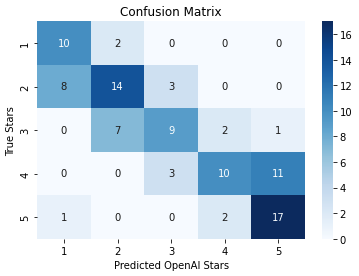
Source: Image created by the author
The matrix shows that the model’s predictions typically differ from actual ratings in the dataset by 1 star. Diving further into this issue, we found the following reviews:
This movie with all of its animals really keeps my grandson occupied when I’m babysitting. He loves watching it over and over again. I can get so much accomplished before he gets bored with it. So, it is worth the money! As a matter of fact, I’m buying one for his house, his 3 y/o cousins’ and my house. We’re saying goodbye to Netflix! Way to go Amazon!! Gammy
Surprisingly, this review is only 3 stars, which is odd, given the tone of this review. Given how it is written, the model assigned to this review 5 stars, which seems appropriate.
This book was in my library’s Genealogy section, and you’re not allowed to take Genealogy books out of the library. But I liked it enough to sit in the library and read it, in two sittings.This a quick read, because it has loads of pictures: photos of the ghetto and its inhabitants, and also pictures of artifacts such as ration cards, work certificates, yellow stars, etc. It’s more like a museum exhibit than a simple book. Because of the format I think young people would be able to get something out of the book too, although it is clearly written for adults. Certainly it probably has the most information on the Kovno/Kaunas ghetto all in one place.Both researchers and the ordinary person interested in the Holocaust would enjoy this.Bonus: pages from the diary of Ilya Gerber are printed in this book; you can read extracts from the diary in Alexandra Zapruder’sSalvaged Pages: Young Writers’ Diaries of the Holocaust.
This review has a rating of 4 stars, while the model assigned it 5 stars.
The best Racket ever made. I’ve been using this model racket for around 15 years and it’s still one of the best rackets ever made by Prince. The Prince Graphite Mid Plus is still one of the stiffest rackets you can get and it also has excellence weight and balance.This racket is more suited to the higher standard player. It provides exceptional control especially with volleys. I have these rackets strung at between 62–64 pounds for hard court and grass court play.It will be a sad day when there are no more of these rackets available.
Given this overly excited text, the model assigned to it 5 stars. However, for some reason, this review is only 4 stars.
This analysis shows that sometimes, the stars of the review do not always clearly correspond to the actual text of the review and are very subjective. LLM’s prediction of the stars is based on the semantics of the review and its interpretation; therefore, its star prediction might better generalize the review context.
Note: LLMs have their own biases, and sometimes they may play a crucial role in the model prediction. So always keep that in mind when working with the LLMs. Don’t take all the outputs for granted.
Extracted metadata
RMSE is not applicable to measure the quality of metadata extraction cause all the fields are either strings or lists of strings. Therefore, we had to represent these strings as vectors and compute their similarity.
To correctly measure the similarity between string values, we must consider underlying context and semantics. We can calculate the angle between two vectors by transforming our strings into high-dimensional embedding representations that capture semantic details. This is a common practice in NLP called a cosine similarity. It is often used to measure similarity between texts. For this cause, we used the OpenAI text embedding model (text-embedding-3-large) to obtain embeddings from strings and computed cosine similarity between them. Cosine similarity is calculated as follows:

Source: Image taken from source
Where A · B is the dot product of vectors A and B, and ||A|| is the Euclidean norm of the vector.
Also, we have a list of strings in some fields. Therefore, there might be situations where there are more strings in the list than in predictions, or vice-versa. To compute metrics, we obtained embeddings of all the strings in the list and obtained a matrix, where (i, j) entry is cosine similarity between i-th entry in predictions and j-th entry in labels.
Taking the maximum value over each row in the matrix gives us the best label correspondence of the predicted vector. Similarly, the maximum value over each column gives us the best correspondence of label vector in predictions. Having separate correspondence from labels to predictions and vice-versa is useful when there is a mismatch in entries in lists (more entries or less). With the best correspondence between vectors, we can calculate average cosine similarity values, precision, recall, and f1 score.
Below is the implementation of the algorithm defined above:
Here are the results obtained for the chosen labeled subset of reviews.
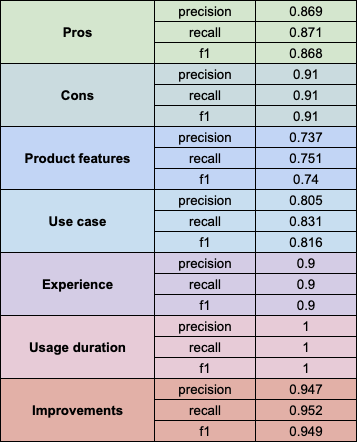
Source: Image created by the author
Conclusion

Source: Image generated by the author using AI (Flux AI)
Our data extraction algorithm with OpenAI’s GPT-4o demonstrated how easily we can gather important metadata from unstructured data for further analysis, while most classical algorithms struggle with this task.
Considering the results, LLM performed well in predicting star ratings and extracting key features from reviews. Furthermore, the model’s predictions of the user feedback rating might hold better justification and lack personal subjectivity. Who knows, maybe soon we will have 2 product ratings (first based on the user scores and the second based on the LLM scoring), or some average value that will be more beneficial to the end consumer.
Overall, LLMs are a powerful tool for businesses to better understand customers’ needs, facilitate analysis, enhance products, and process large amounts of unstructured data faster.
All the labeled data alongside the code can be found on the Drive.
you might also like…

Realtime presentation transcription and clear meeting summary using GPT4
Introduction Almost no one can imagine our life without presentations and demos via videoconferences. With this in mind, think about... Read more

From Retrieval to Intelligence: RAG, Agent+RAG, and TruLens
Unlocking the Power of GPT-Generated Private Corpora Introduction Nowadays the world has a lot of good foundation models to start... Read more