

Recently, we were tagging a lot of texts with spaCy in order to extract organization names. We faced a problem: many entities tagged by spaCy were not valid organization names at all. And it wasn’t actually the problem of spaCy itself: all extracted entities, at first sight, did look like organization names. The result could be better if we trained spaCy models more. However, this approach required a large corpus of properly labeled data which should also include a proper context. So we needed a simpler solution to filter out the wrong data.
you might also like…
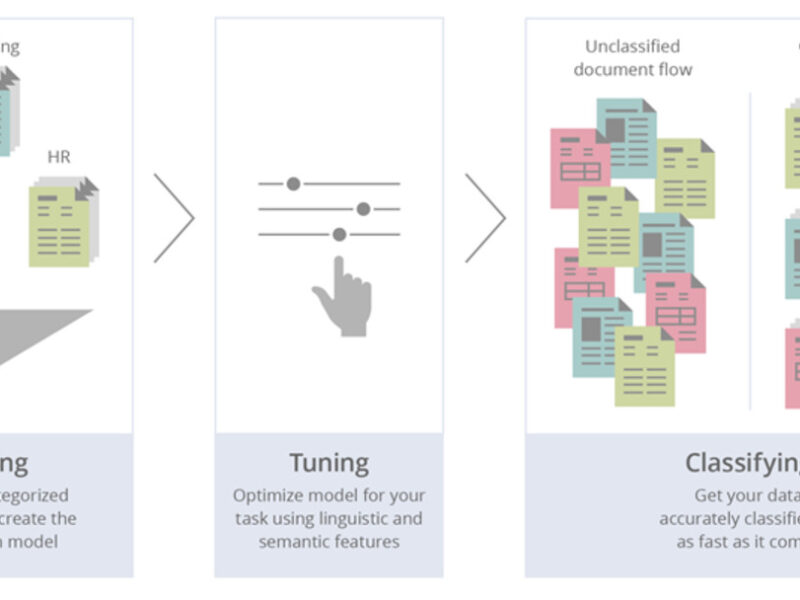
Automated Document Classifier Solution For Banking
Our Main Challenges in Document ClassificationA retail bank addressed MindCraft asking for help with document classification. Their organization has an... Read more

Predictive Sales Analytics Tool for Special Offers Evaluation
This machine learning tool doesn’t replace the professional employee with the knowledge of the industry. However, Predictive Sales Analytics it... Read more