
Subject: Automated Document Classification, Document Capturing, Data Extraction, AI Document Recognition
Business Areas: Banking, FinTech, Retail
Data Science Areas: Computer Vision, Machine Learning
Tools: Python, Tensorflow, Sklearn, Tesseract
Summary: MindCraft helped to automate the document capture and recognition for a client in the Banking industry using AI Document Recognition Software. The system can process documents for any domain and containing any kind of content, from handwritten text to fields and tables.
The Challenge off AI Document Recognition Software
Our client has been in the market of banking and finance services for over 10 years. They asked us to come up with a machine learning solution to simplify their document recognition and classification procedure. Every day the company had to process a few thousands units of business data. A substantial team of people performed this manually, which was both time-consuming and costly. Our main task was to develop a Machine Learning solution to streamline document processing and sorting and minimize the need for manual operations.
Data Extraction: Complexity and Risks
The automatic classification of administrative documents is a rather complicated task. It presupposes varied papers coming from multiple suppliers. All those documents have different visual parameters: size, format, paper color shade, font size, and type. The essence of the information contained in the document also varies. The fact that part of the documents is handwritten only makes things more complicated. Often it was very hard to make out the writing.
Stage One: Digitalizing The Content
Before our Machine Learning developers could proceed with digital processing of accounting and other documents, we needed to digitalize the content of all fields. Manual input is not an option if there is a lot of data. To enable the automatic input, you need to solve two tasks first:
- OCR
- The understanding of which field contains info and where it is located
An example:

We started with the analysis of invoices and searching for fields with suppliers’ names, dates and document numbers. The documents vary to a great extent and new documents are to be expected. That is why it is almost impossible to solve this task by the software implementation of rigid algorithmic solutions. Intellectual data management methods, Machine Learning, in particular, appear as a reasonable alternative.
Data Processing Accuracy
We had a selection of 500 real business documents to work with. The training selection had 400 documents from different suppliers. The test set consisted of 100 such documents.
Conditional Random Field (CRF) is a well-known method for tasks like this. Conditional Random Field has often applied in pattern capture and recognition and Machine Learning solutions and is used for structured prediction. The method is based on the analysis of the content of the field itself. However, in practice, the quality results of this method are not very impressive. The possibility to find the right document number on a test set didn’t exceed 55%, 62% of the date detection accuracy. The fields with organization name were easier – 85%
Obviously, the location of fields on the document has its own patterns, hidden at first glance. So the second model used fields location on the document and also fonts characteristics as factors. Random Forest classifier was a basis for this model. In the end, though, the results were also not that high.
We managed to improve the result significantly only by combining the achievements of both models. The outcome – at least 70% of correct field recognition
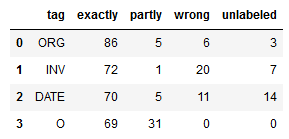
Results of AI Document Recognition
Getting these results helped us understand that the client’s idea is absolutely real and we can implement it. The data extraction software became only the first part of the big work that we did for the client. The second part of the project was Automated Document Classification Solution For Banking
We managed to make the client’s idea a reality and exceed their expectations. As a result, our client received a system which will help their business with automated document classification. With our Machine Learning-based software taking care of document processing, our client can now concentrate on business strategy and other mission-critical tasks.
you might also like…
Automated Document Classifier Solution For Banking
Subject: Automated Document Classification, Document Capturing, Data Extraction, AI Document RecognitionBusiness Areas: Banking, FinTech, RetailData Science Areas: Computer Vision, Machine... Read more

Vectorization of Raster to Polygons
Subject: Automated Document Classification, Document Capturing, Data Extraction, AI Document RecognitionBusiness Areas: Banking, FinTech, RetailData Science Areas: Computer Vision, Machine... Read more